ELK专题:Day6——使用Kibana创建分级统计图(choropleth)
1. 前言
一说起分级统计图,大家可能会觉得陌生,但要是我说是类似疫情地图那种图,大家可能一下子就反应过来了。没错,分级统计图就是类似这样的图:
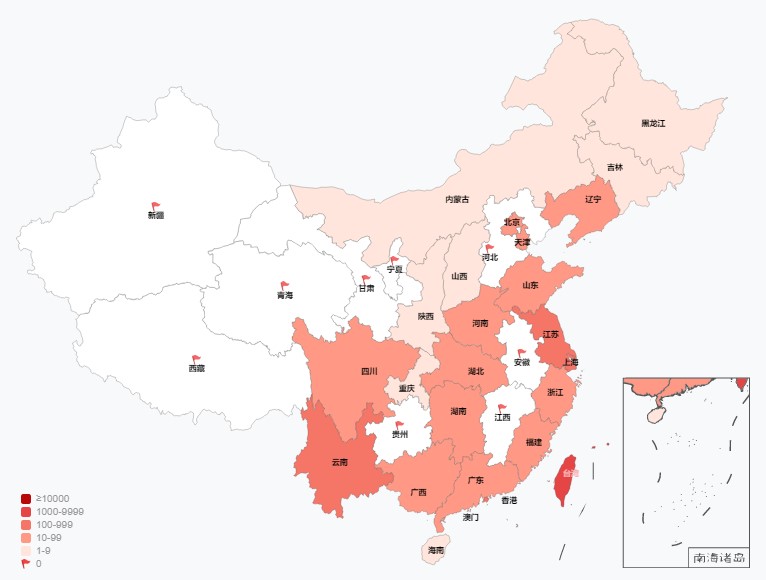
在进行数据分析的时候,这种结合地图色块的呈现方式能很直观地反映数据和地区的联系,让人能一眼看出各个地区的差异,也常常用于对各个地区进行数值比较的场景中。
今天我们就用分级统计图来呈现我们这个网站在各个地区的热度。
2. 准备工作
2.1 实现原理
在Kibana中集成的地图服务里面,已经预设了部分常用的地图数据,只要我们存储的数据里面包含符合要求的地理位置信息,就可以和地图中的地块信息进行关联,生成我们需要的分级统计图,叠加在地图上。
在默认情况下,Kibana会遍历索引里面的所有文档,分别统计符合各个地块标记的数据条数,最后把统计结果通过颜色或者是数字呈现在地块中。
2.2 确定地图维度
和我们上次做数据分析一样,尽管我们已经知道Kibana中的地图服务集成了大量的预设地图数据,但是在开始之前,我们仍然需要明确我们到底是需要什么样的统计结果。在本次实验中,我们将会以世界地图和中国地图各进行一次展示。
2.3 确定地图信息标记
正如上文提到的,在我们确定统计精度之后,就需要知道各个地块是以什么方式去标记的。比方说,我即将要统计美国各个州份的人口数据,并且要在地图上以分级统计图的方式呈现出来,那我就要知道Kibana是如何识别地图中的地块信息的。这些信息我们都可以在Elastic Maps Service页面中查到。
如在下图的例子中,美国的怀俄明州的地区编码是US-WY,邮政编码是WY,我们就使用这些信息去标记一个地块(Administrative boundaries)。
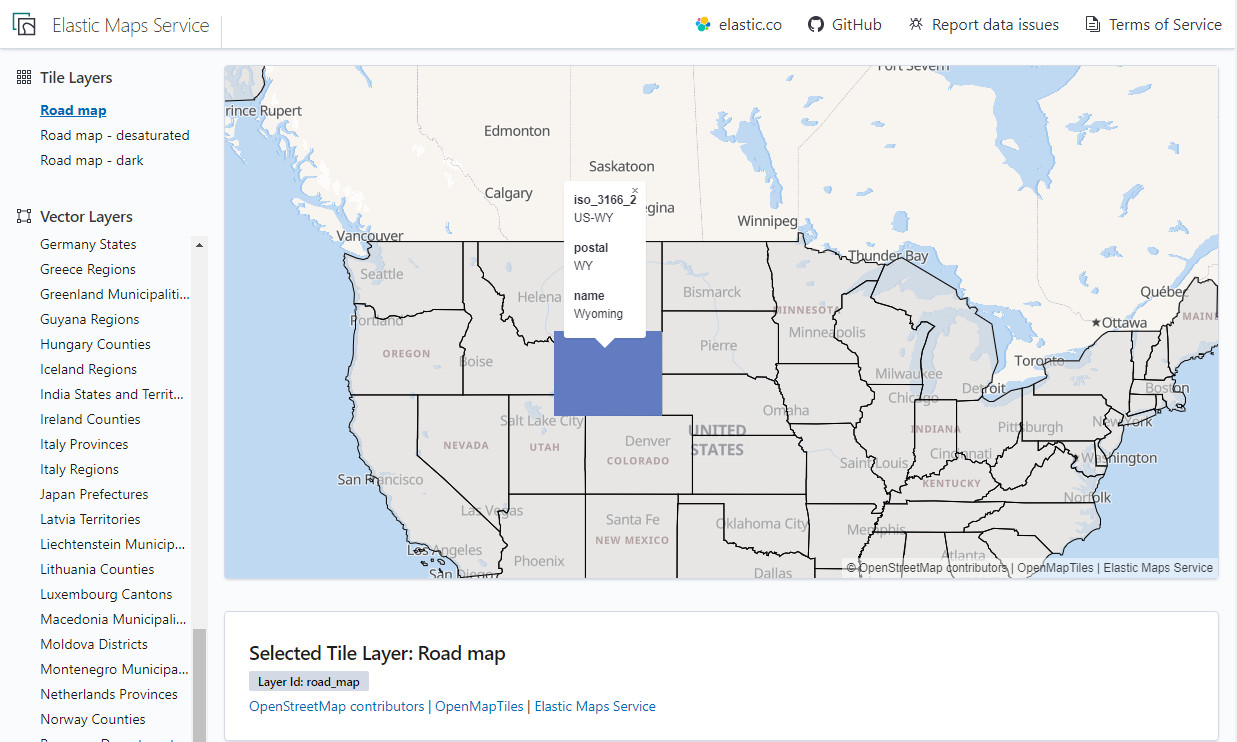
在Elastic Maps Service中,每一块地区的分界线信息会以JSON的格式存储,用一组数列收录边界上的一部分坐标点数据,再通过连线形成一个区域的边界。
点击展开完整json
1 | { |
2.4 索引数据中的位置信息
我们在之前的文章《ELK专题:Day3——Logstash & Filebeat 配置补充》中有介绍,通过日志里面的IP地址查出位置信息,并保存到ES索引中。
3. 设置步骤
3.1 对各个国家或地区统计网站访问量
在Elastic Map Service中可以看到,世界地图使用ISO 3166-1 alpha-2 code作为国家代号,中国就是CN。
另外,在我们ES索引的文档数据里面,在字段geoip.country_code2中会包含国家代码信息:
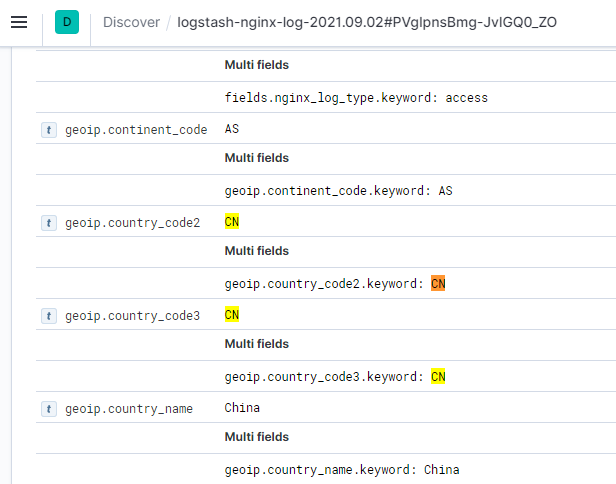
操作步骤如下:
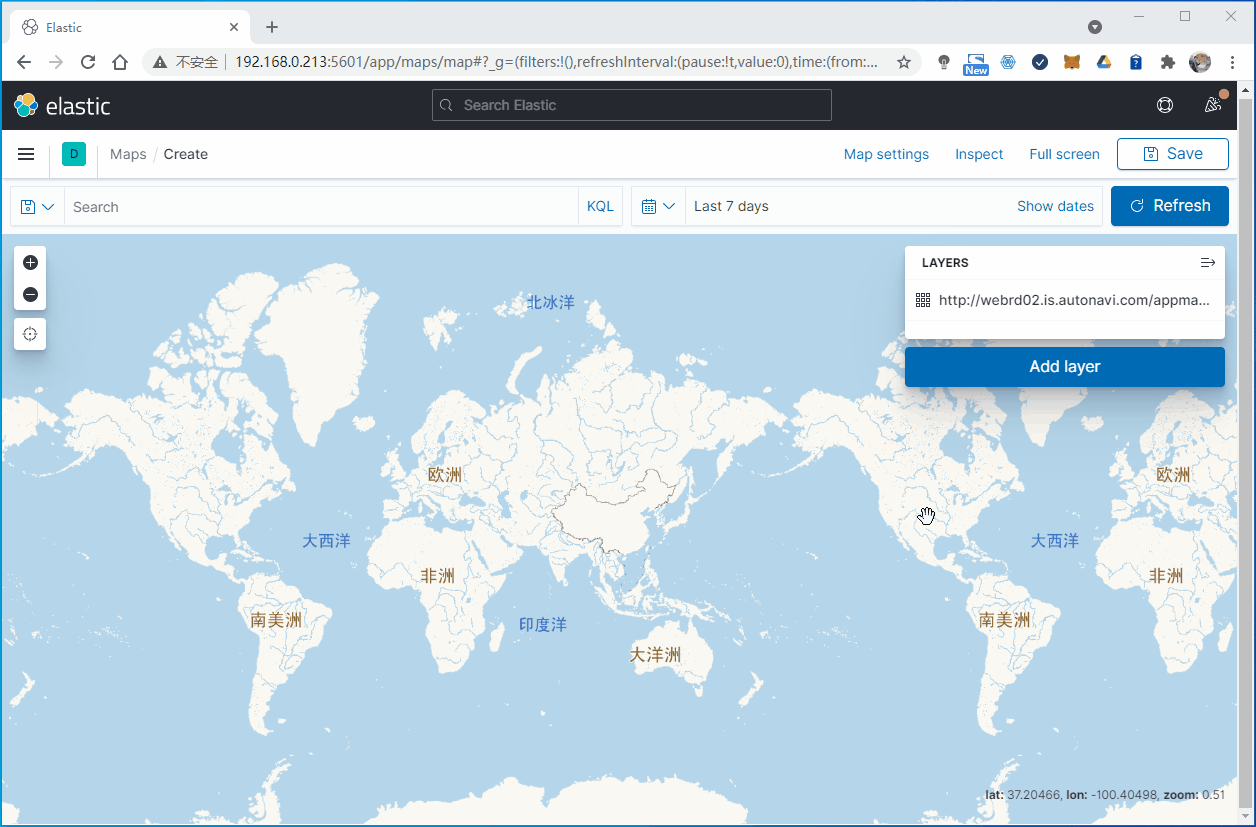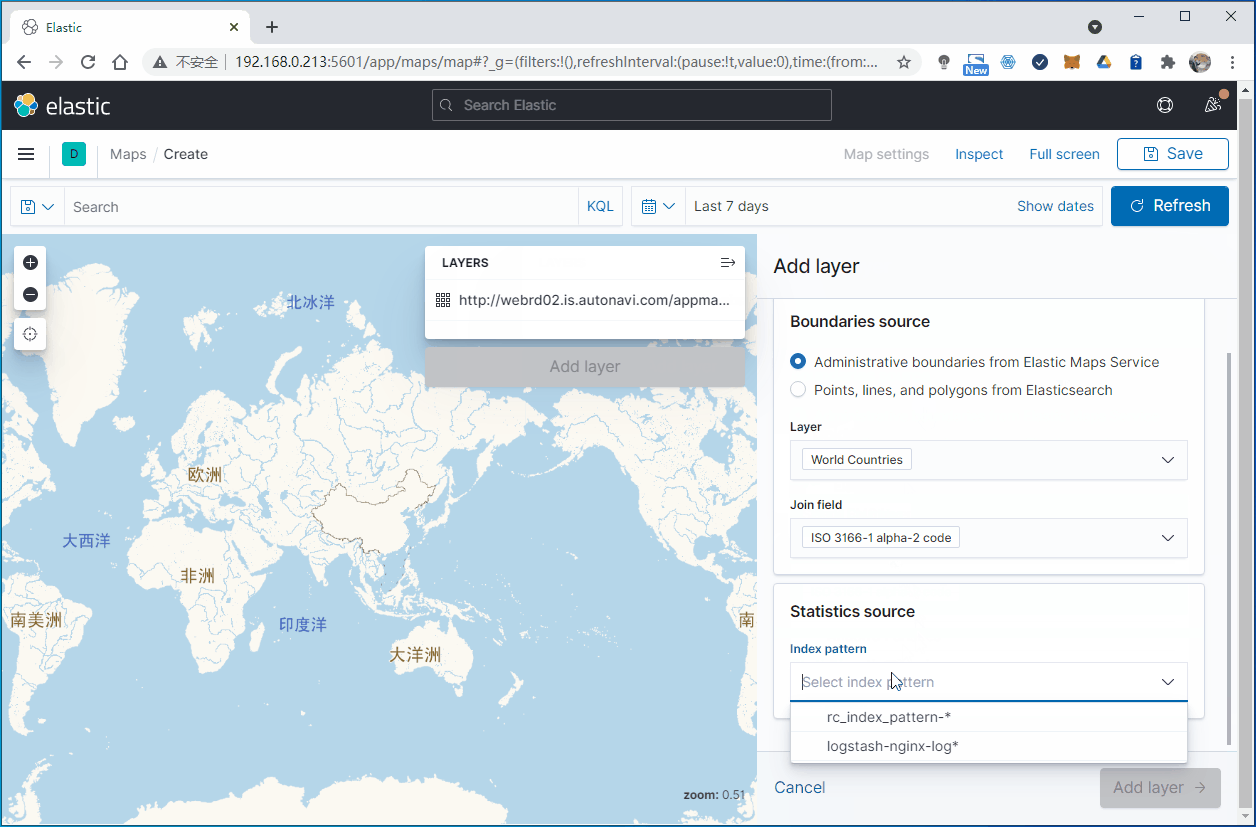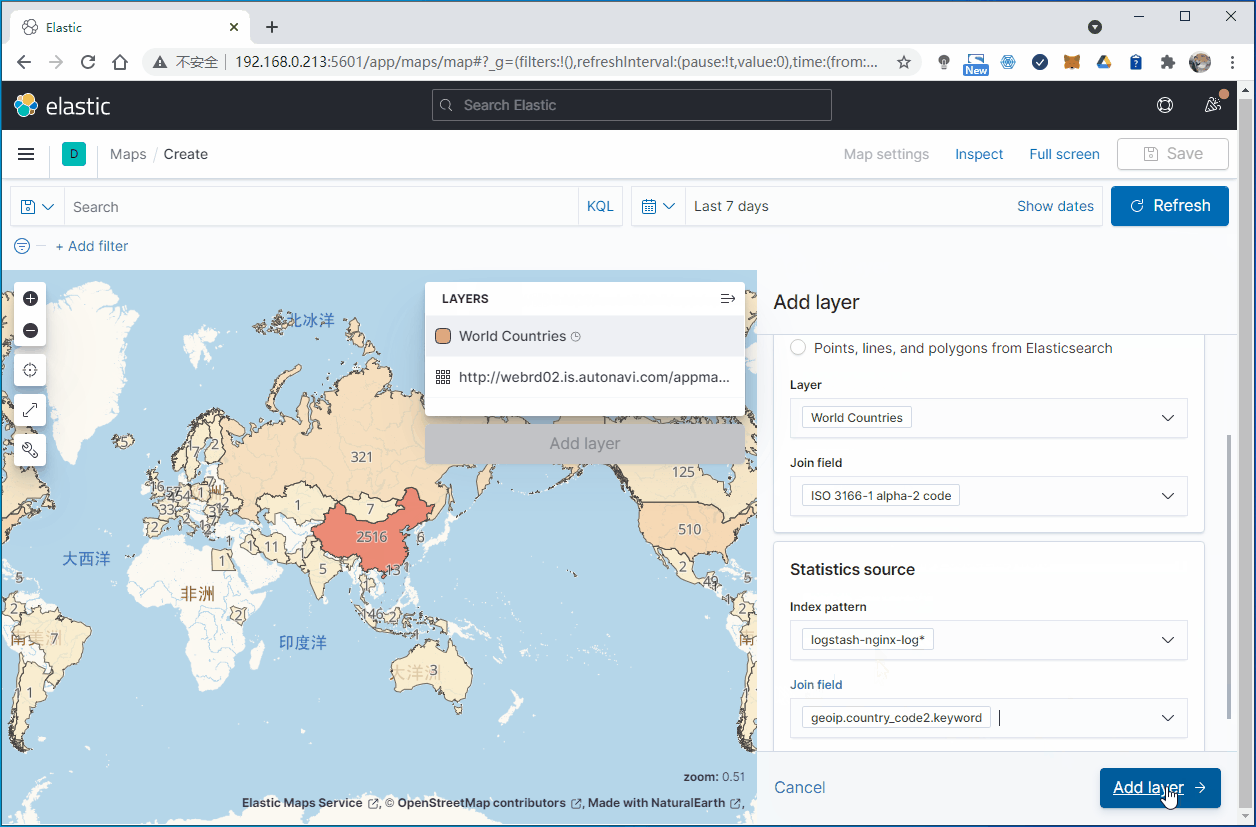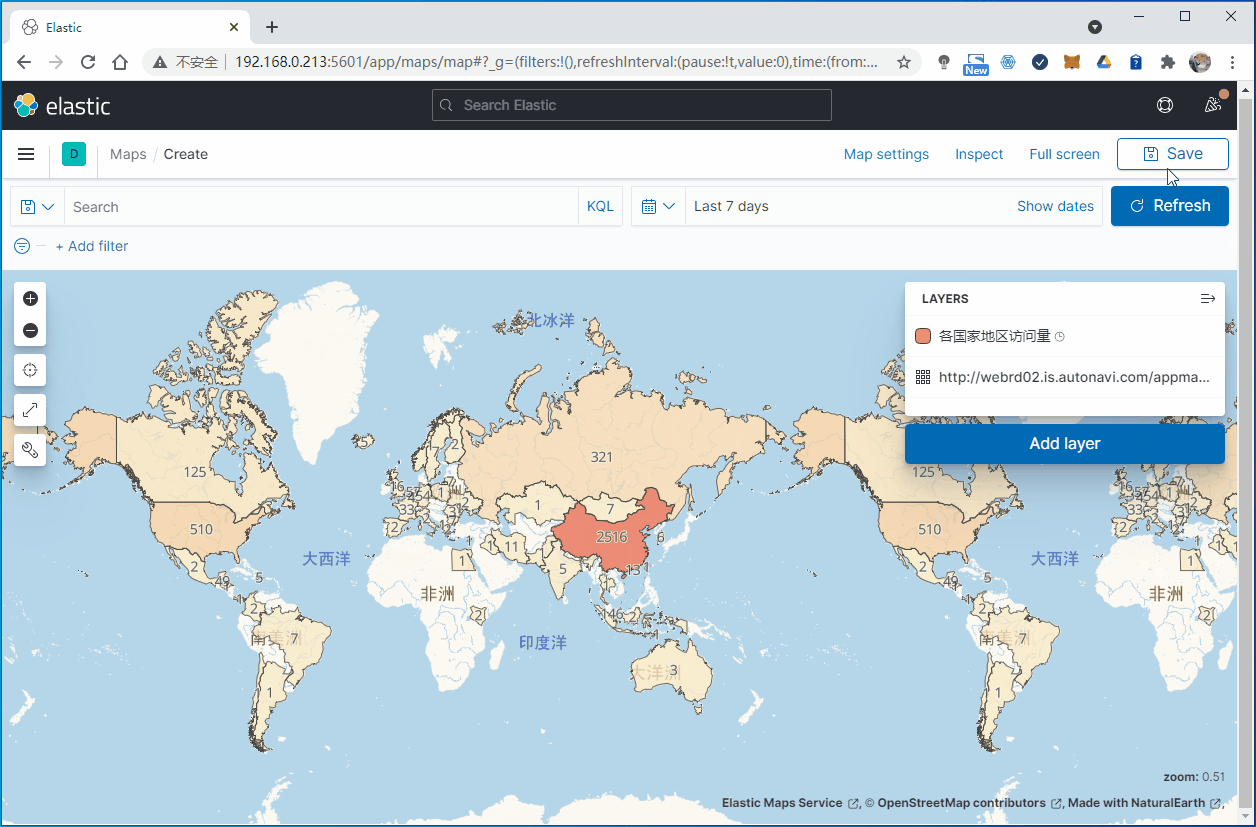
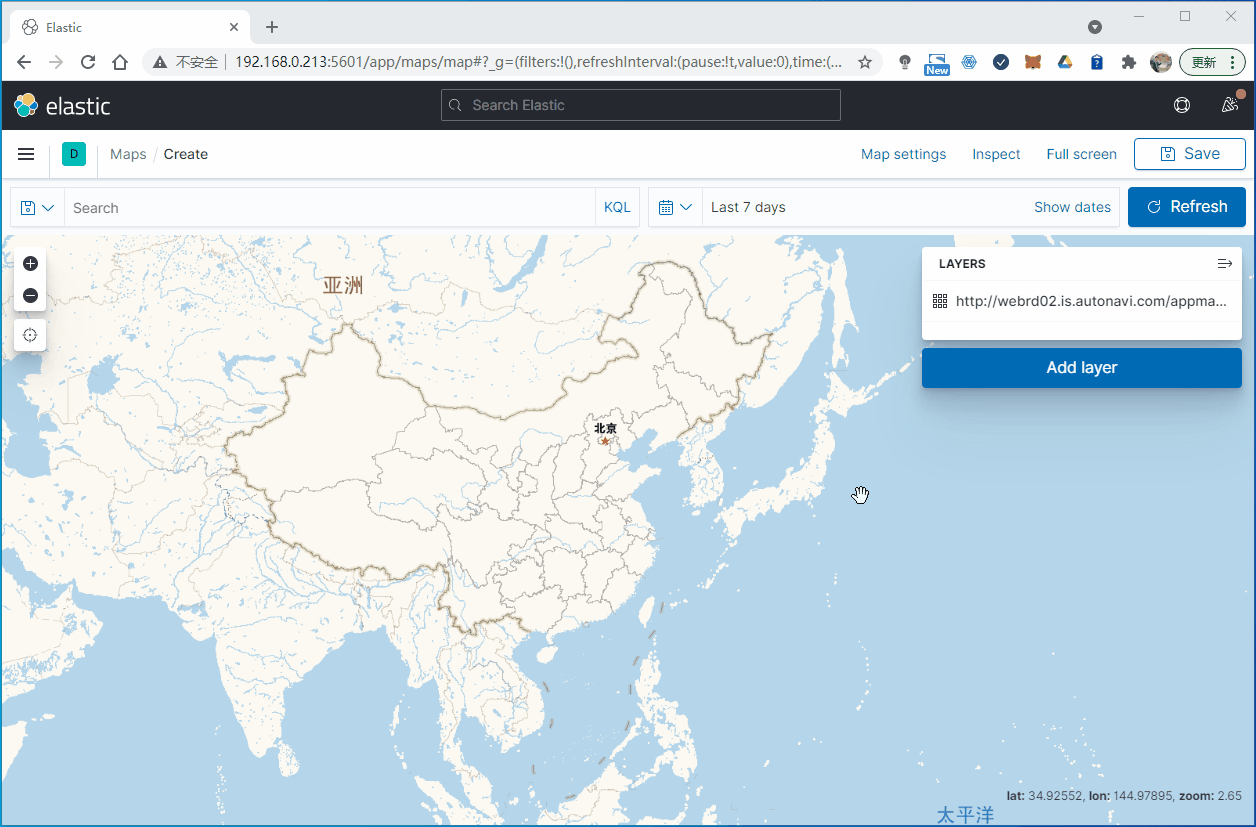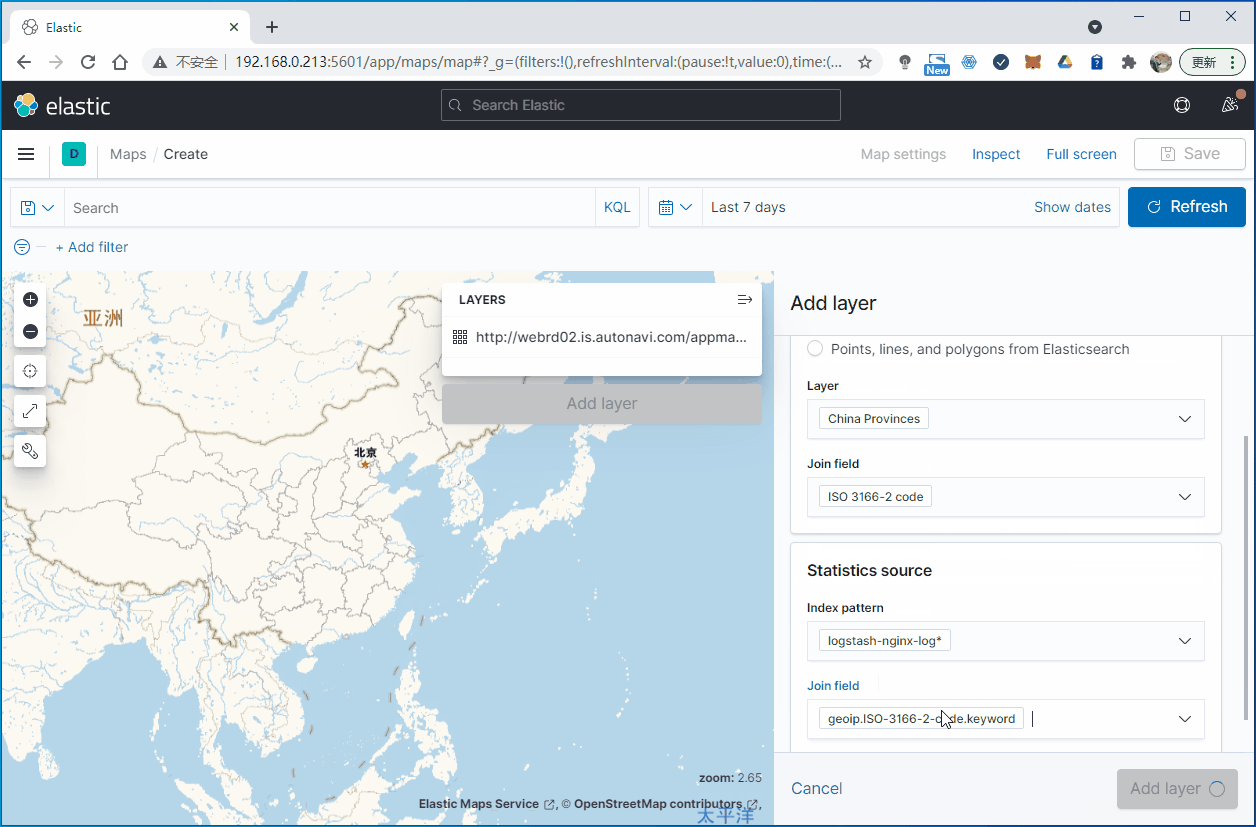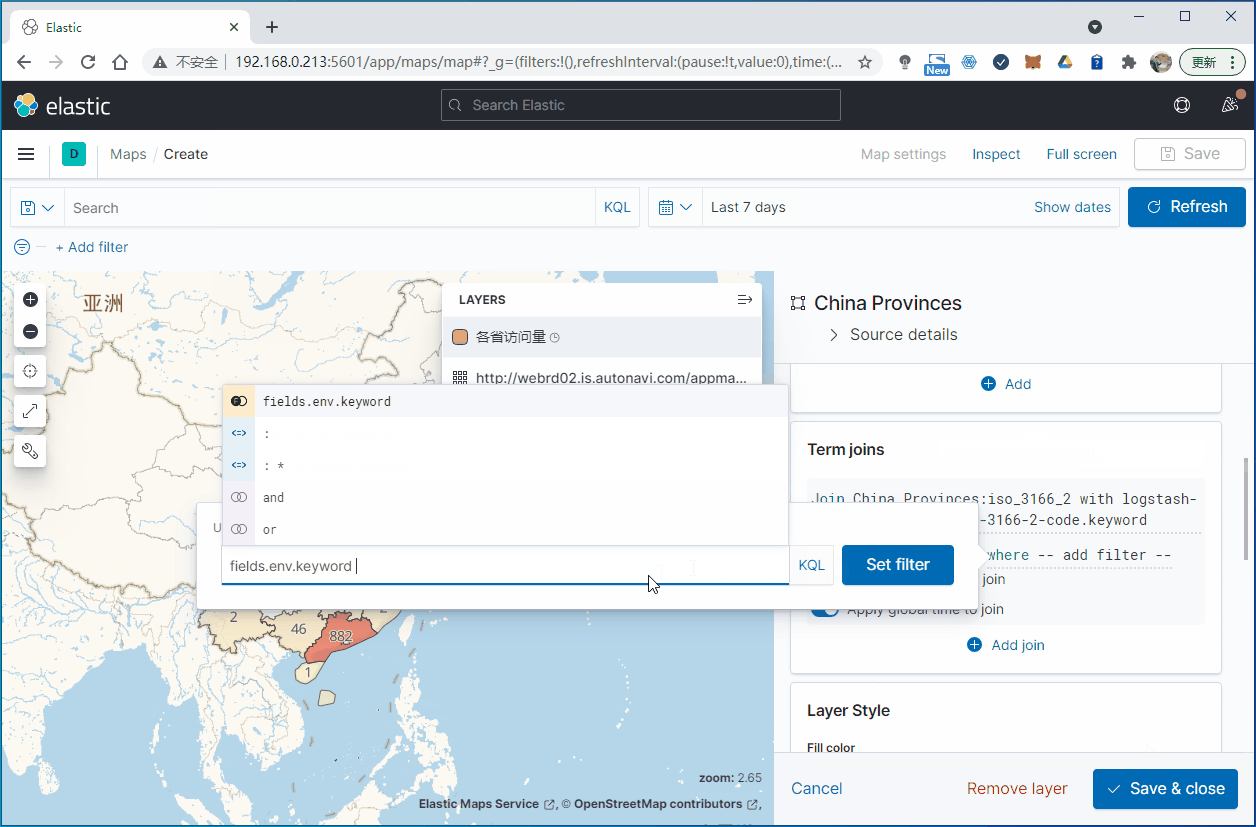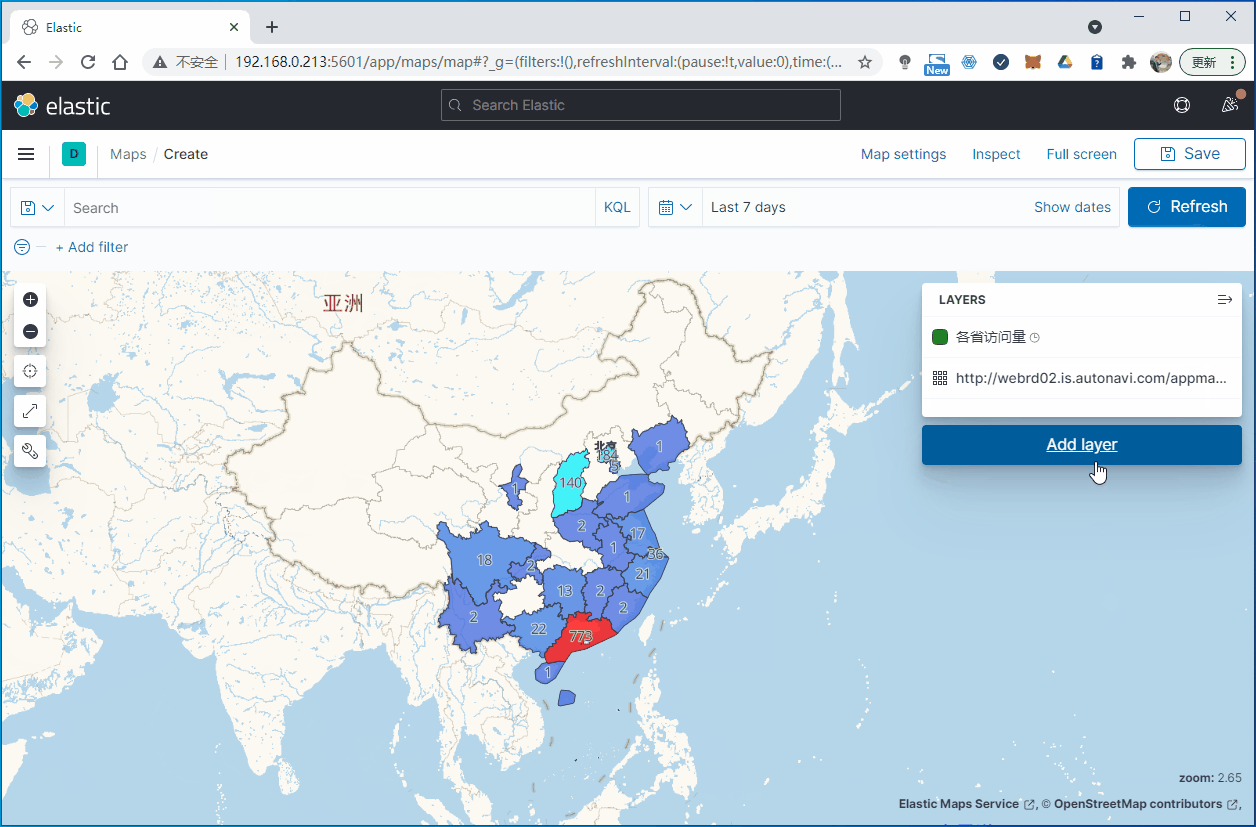
3.2 统计各个省份的访问量
原理是一样的,但是在省份的这个维度下,需要一些额外的操作。
3.2.1 关于省级行政区域图中的Region code
我们在Kibana的地图功能里面会看到,预设了中国的省级行政区域图(China Provinces),我们可以看到,是使用ISO 3166-1 alpha-2 code来标记各个省份,比如说,浙江省的代码就是CN-ZJ。
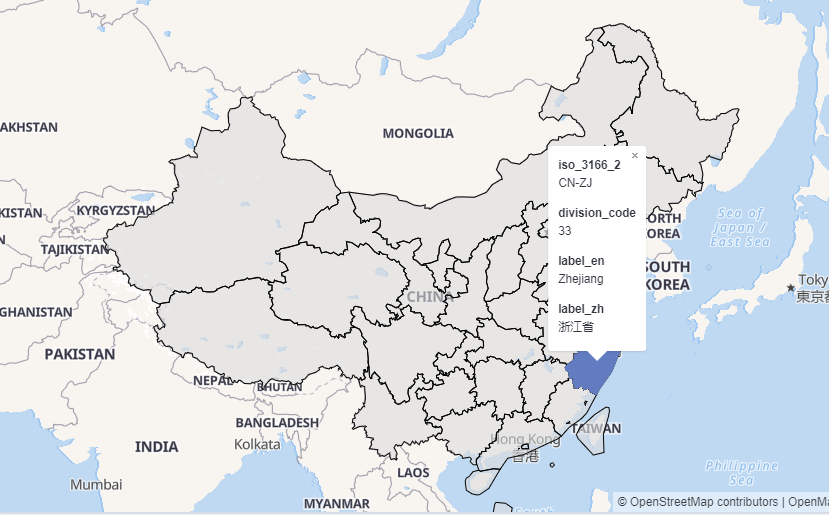
3.2.2 Geoip插件的字段设置
我们在《ELK专题:Day3——Logstash & Filebeat 配置补充》中关于geoip的配置中会看到,geoip插件默认返回的字段内容有:
1 | { |
不难看出,为了和elastic map中的ISO 3166-1 alpha-2 code匹配,我们需要把country_code2和region_code结合起来,生成CN-GD这样的内容。所以,我们需要在logstash的配置中增加一个组合字段,配置示例如下:
1 | input {} |
修改完logstash配置后别忘了重启服务
3.2.3 flush ES索引(可选)
如果logstash的新增字段没有生效,可以尝试对索引进行一次flush操作。笔者现阶段对ES的研究还很有限,暂时未确定flush具体的作用和原理,先挖一个坑,后面有机会再仔细研究。
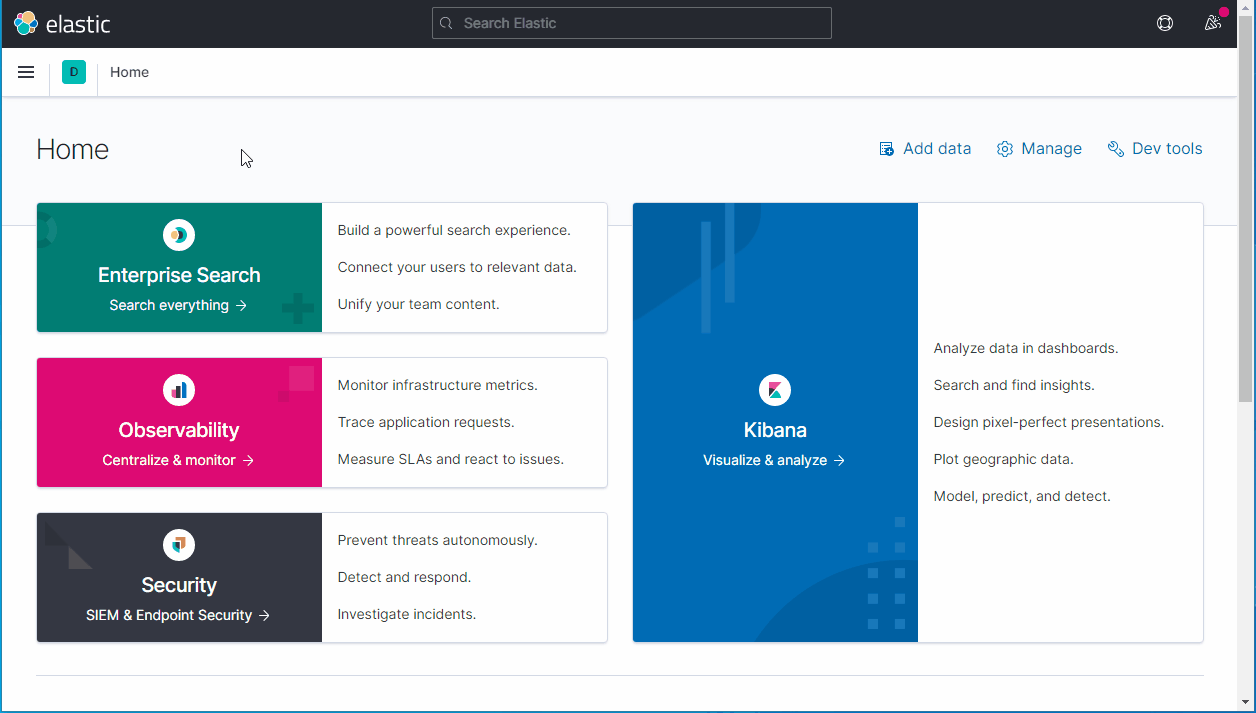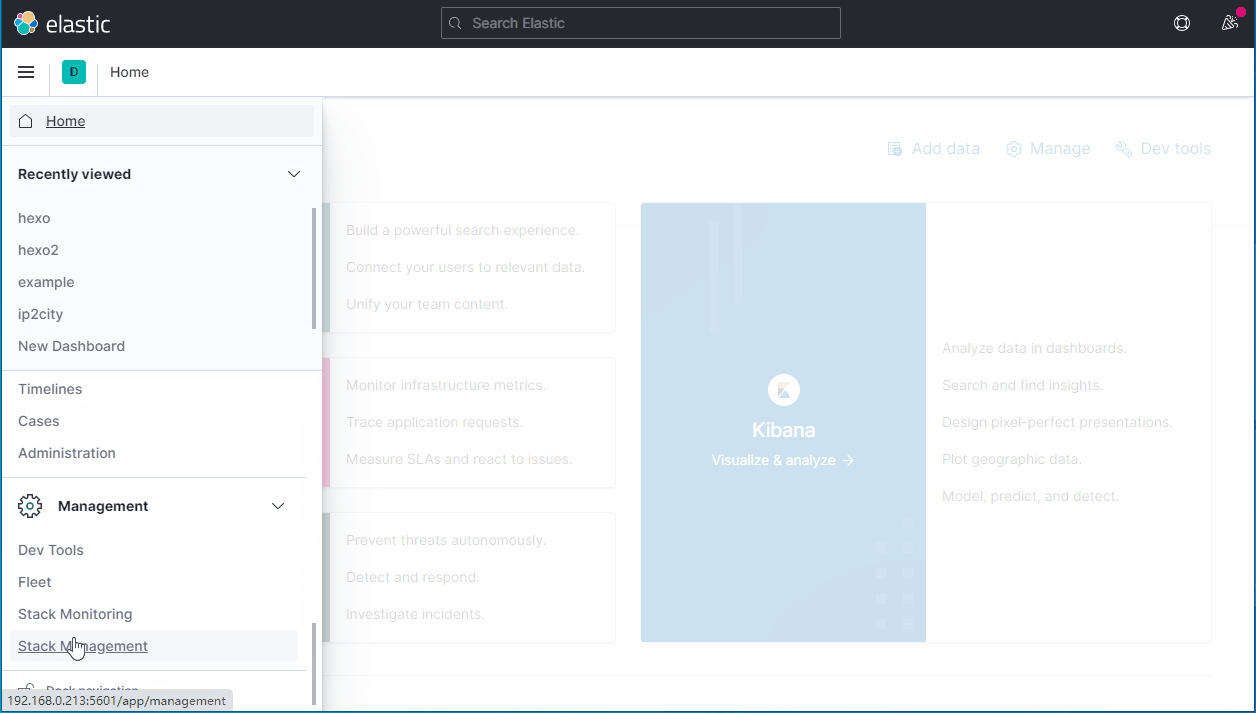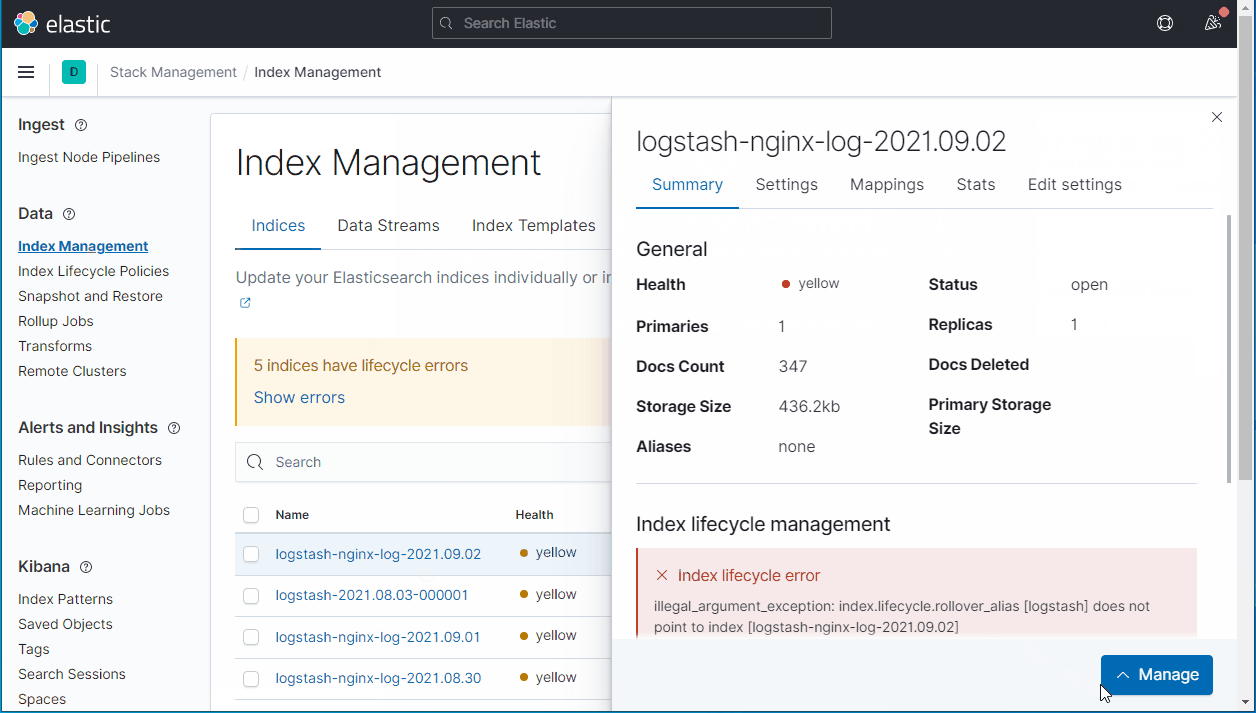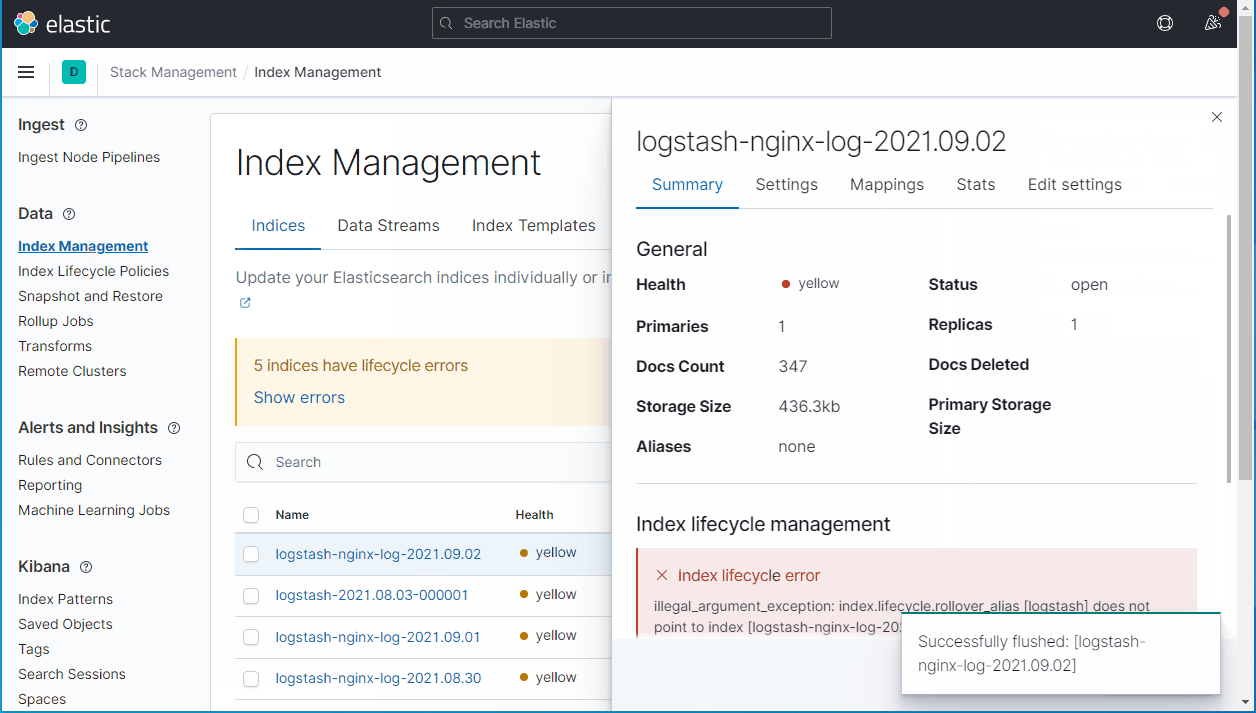
如果一切正常,最后我们会在ES索引中得到新字段geoip.ISO-3166-2-code:
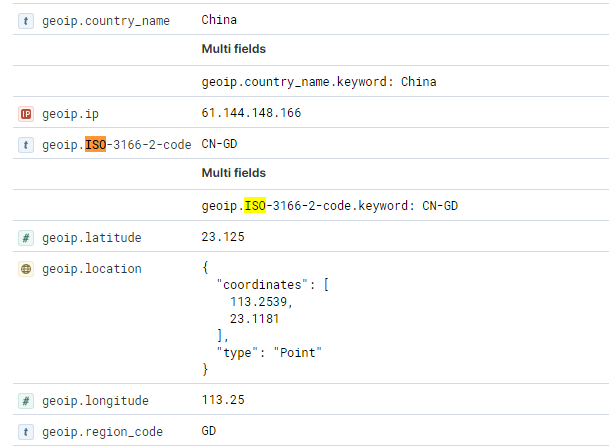
3.2.4 创建图层展示各省访问量
操作步骤如下:
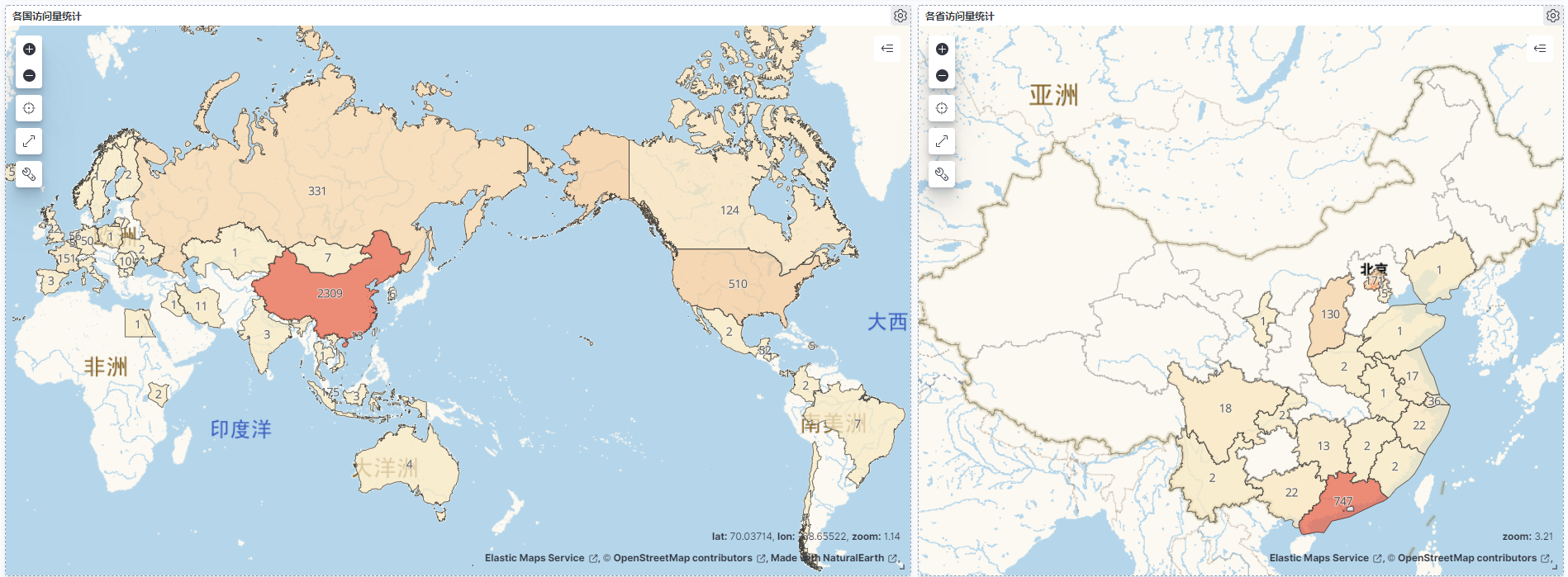
4. 总结
继热力图之后,我们又学会了使用分级统计图去进行可视化输出了。通过这个强大的工具,不仅可以快速生成美观的统计图,还能帮助我们直观地了解到我们需要的业务数据,是进行数据分析时候不可或缺的工具。(怎么觉得有点尬聊的感觉?)
ELK专题到目前为止,已经完成了从日志采集、存储、检索到可视化的整个流程。假如是以一个项目的筹备阶段去看待,现在这一套方案已经可以勉强满足初步的上线运营需求。
值得补充的是,在我们使用Geoip插件的时候,会遇到IP地址识别失败或者是位置不准确的问题。在现实中,IP地址本来也不作为一个定位工具,geoip databases记录的数据会存在误差。在geoip的娘家MAXMIND里面有对这种现象进行说明(ip-geolocation-accuracy),同时也可以参考GeoIP2 City Accuracy查询某一地区对IP地址识别数据的准确率。
下一步,我们将会回过头来巩固基本功,做一些性能分析,看看我们这个ELK的瓶颈在哪里,以及,应该如何去优化。