前言 数据分析大家应该都经常听说了,算命甚至是自古有之,那不知道大家有没有想过,用数据分析的思路去对算命结果进行统计,会有什么奇妙的化学反应。
在本文,笔者将会使用Python和MySQL结合,以《袁天罡称骨歌》为依据,对1901-2081这三个甲子的所有生辰八字进行一次运算, 对算命结果进行一次统计。
袁天罡称骨算命法 孔子曰:”不知命,无以为君子。”
简单来说,袁天罡的称骨算命法是通过一个人出生的年月日和时辰去加权求和计算出骨重,继而得出结果。总体而言,重量越大,命越好。
例:一人出生在甲子年正月初一日子时。
甲子年骨重一两二钱,正月骨重六钱,初一日骨重五钱,子时骨重一两六钱。年、月、日、时骨重加在一起(1.2+0.6+0.5+1.6=3.9),此人总骨重是三两九钱。查看三两九钱的”称骨歌”,就是这个人一生的命运。
详情可见:百度百科:袁天罡称骨歌
代码 本统计将会使用Python编写的简单脚本完成,统计结果保存到关系型数据库MySQL。
考虑到只是一个小脚本,就不上传到GitHub了,下载地址:
yuantiangang.py commondata.py
安装好必要的依赖之后,直接运行yuantiangang.py即可。
农历和时辰的处理 在统计过程中,笔者使用Python的datetime库完成日期和时间的遍历,datetime中的公历时间将会使用开源项目cnlunar 转成农历.
1 2 3 4 5 6 7 8 9 10 import cnlunarimport datetimea = cnlunar.Lunar(datetime.datetime(2022 , 11 , 14 , 10 , 30 ), godType='8char' ) dict2 = { '日期' : a.date, '农历数字' : (a.lunarYear, a.lunarMonth, a.lunarDay, '闰' if a.isLunarLeapMonth else '' ), '农历' : '%s %s[%s]年 %s%s' % (a.lunarYearCn, a.year8Char, a.chineseYearZodiac, a.lunarMonthCn, a.lunarDayCn) } print (dict2)
运行结果:
1 {'日期': datetime.datetime(2022, 11, 14, 10, 30), '农历数字': (2022, 10, 21, ''), '农历': '二零二二 壬寅[虎]年 十月大廿一'}
对象设计 为完成运算,创建一个名为Shengchen(生辰)的对象,对象初始化的时候,具有对象属性:
date: 一个datetime对象,记录一个出生时间lunarData: 通过cnlunar.Lunar方法,把标准日期转为农历
为对象设计下列各个方法完成算命运算:
hour_to_shichen: 把标准时间转成十二时辰,返回一个在range(0,12)的整数get_year_weight: 获得生辰年份所对应的骨重get_month_weight: 获得生辰月份所对应的骨重get_day_weight: 获得生辰日子所对应的骨重get_hour_weight: 获得时辰对应的骨重get_total_weight: 把年月日时辰的骨重进行加总insert_into_db: 将计算结果插入MySQL
算命计算方法 这个算命方法本质上说就是一个加权求和的过程: 年、月、日、时辰分别对应不同的权重,最后进行加总。
为了优化运算效率,所有的权重值使用整数记录,例如: 正月的骨重是6钱,记作6,辛酉年的骨重是1两6钱,记作16。
程序为了记录各个权重值,使用一个外部文件记录四个变量:
年: weight_of_year = ({"name": '甲子', "weight": 12},{"name": '乙丑', "weight": 9},...,)
月: weight_of_month = (6, 7, 18, 9, 5, 16, 9, 15, 18, 8, 9, 5)
日和时辰的权重和月的类似。
以get_month_weight方法为例,只需要简单地通过元素的序号,即可获得对应的骨重:
1 2 def get_month_weight (self ): return weight_of_month[self.lunarData.lunarMonth - 1 ]
批量计算 创建一个函数,通过一个while循环,计算从1901年1月1日开始的三个甲子的所有生辰,时间粒度是时辰,所以是每两个小时一条数据:
1 2 3 4 5 6 7 8 def calculate_180_years (): start_date = datetime.datetime(1901 , 1 , 1 , 0 , 0 , 1 , 0 ) end_date = datetime.datetime(2081 , 12 , 31 , 23 , 0 , 1 , 0 ) while start_date <= end_date: shengchen1 = ShengChen(start_date) shengchen1.insert_into_db() start_date = start_date + datetime.timedelta(hours = 2 ) print ('finish!' )
结果存储和统计 数据库设计 只需要使用一个shengchen表即可:
1 2 3 4 5 6 7 8 9 10 CREATE TABLE `shengchen` ( `key` int(11) NOT NULL AUTO_INCREMENT, `datetime` datetime DEFAULT NULL, `year8Char` varchar(45) DEFAULT NULL, `lunarMonth` varchar(45) DEFAULT NULL, `lunarDay` varchar(45) DEFAULT NULL, `shichen` varchar(45) DEFAULT NULL, `weight` int(11) DEFAULT NULL, PRIMARY KEY (`key`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
入库结果 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 mysql> select * from shengchen limit 10; +-------+---------------------+-----------+------------+----------+---------+--------+ | key | datetime | year8Char | lunarMonth | lunarDay | shichen | weight | +-------+---------------------+-----------+------------+----------+---------+--------+ | 15502 | 1901-01-01 00:00:01 | 庚子 | 11 | 11 | 0 | 41 | | 15503 | 1901-01-01 02:00:01 | 庚子 | 11 | 11 | 1 | 31 | | 15504 | 1901-01-01 04:00:01 | 庚子 | 11 | 11 | 2 | 32 | | 15505 | 1901-01-01 06:00:01 | 庚子 | 11 | 11 | 3 | 35 | | 15506 | 1901-01-01 08:00:01 | 庚子 | 11 | 11 | 4 | 34 | | 15507 | 1901-01-01 10:00:01 | 庚子 | 11 | 11 | 5 | 41 | | 15508 | 1901-01-01 12:00:01 | 庚子 | 11 | 11 | 6 | 35 | | 15509 | 1901-01-01 14:00:01 | 庚子 | 11 | 11 | 7 | 33 | | 15510 | 1901-01-01 16:00:01 | 庚子 | 11 | 11 | 8 | 33 | | 15511 | 1901-01-01 18:00:01 | 庚子 | 11 | 11 | 9 | 34 | +-------+---------------------+-----------+------------+----------+---------+--------+ 10 rows in set (0.00 sec)
统计 最后一共进行了793320次运算。
1 2 3 4 5 6 7 mysql> select count(datetime) from shengchen; +-----------------+ | count(datetime) | +-----------------+ | 793320 | +-----------------+ 1 row in set (0.22 sec)
数据分布 1 select count(weight), weight from shengchen group by weight order by weight;
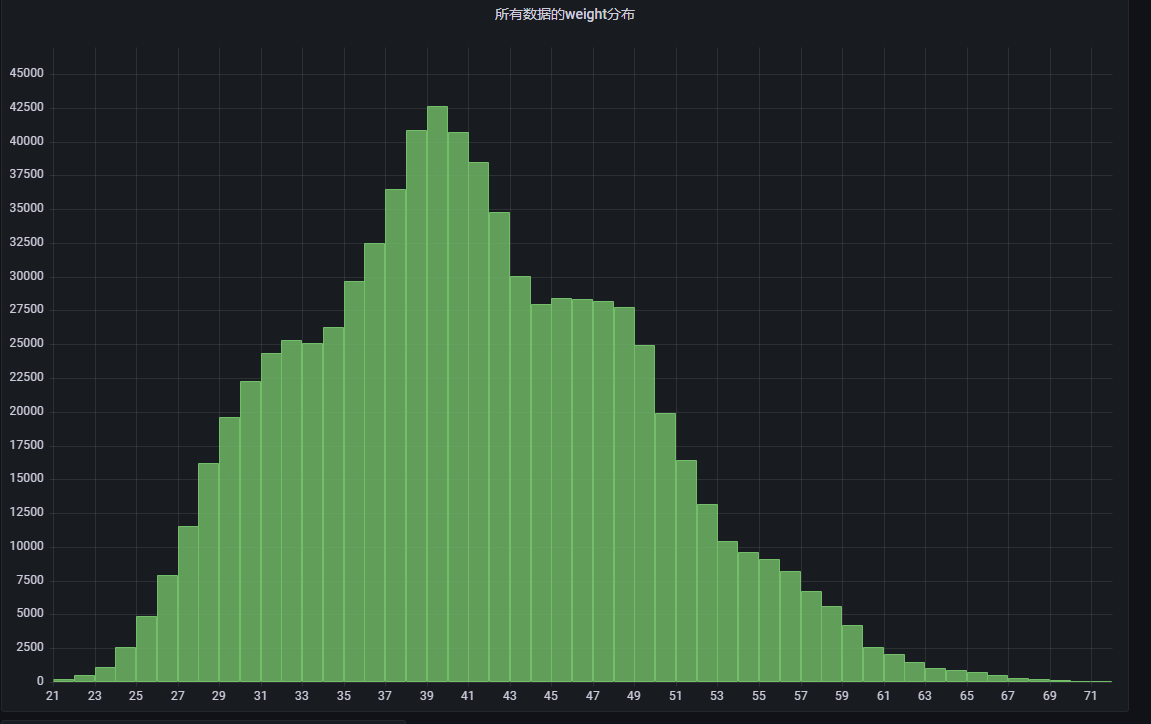
将查询结果进行可视化之后,获得的直方图如下:
粗略看,大致上是呈正态分布,也算是符合直觉,大多数人都是在中游徘徊,比上不足比下有余,众数是三两九钱。
虽说是正态分布,但是整个直方图总体来说是偏左的,毕竟负重前行的才是大多数。
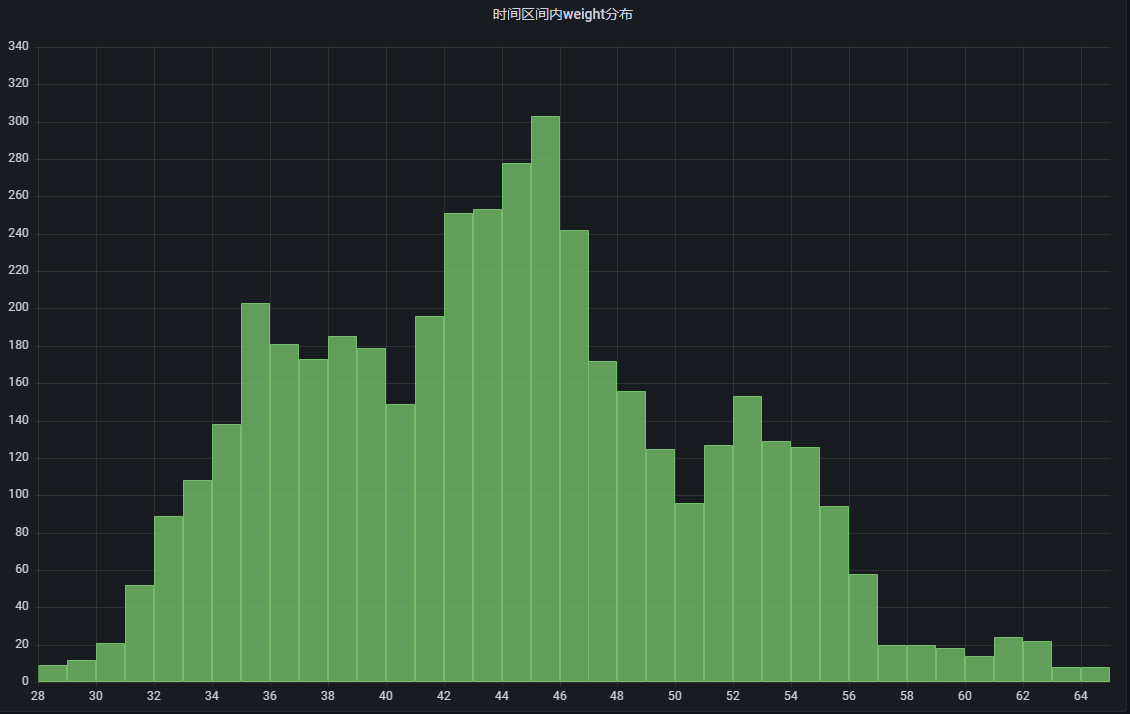
而如果把时间范围聚焦到比较短的时间,比如2000年一年内,分布就不均匀了:
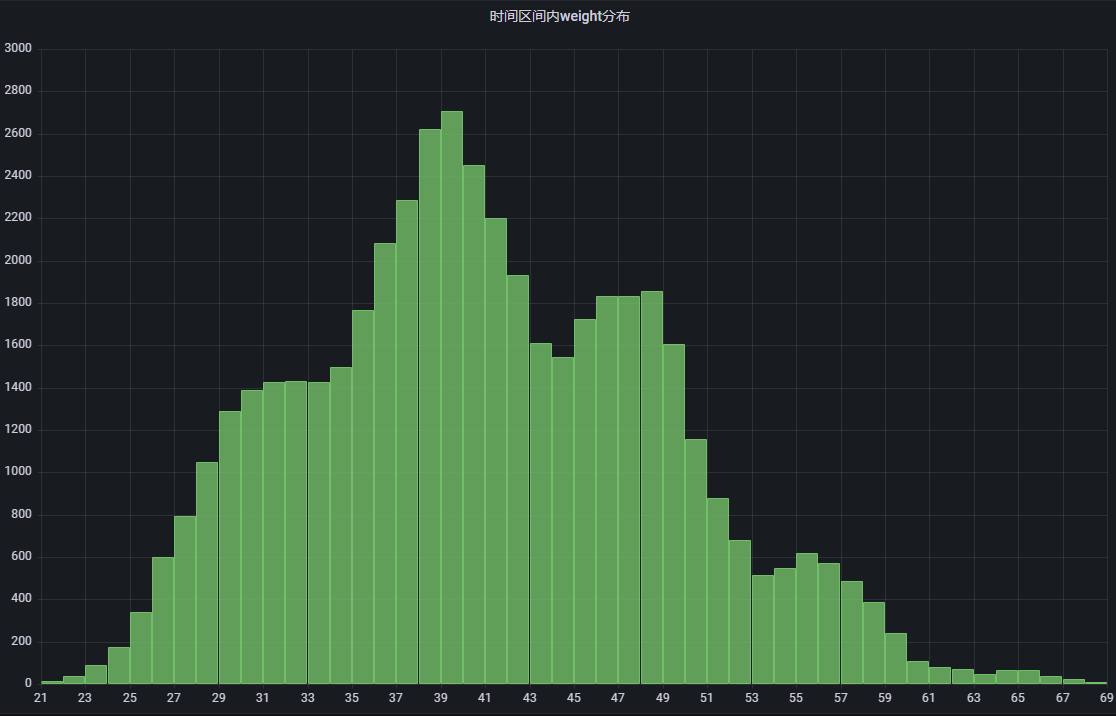
再把时间延长到2000年到2010年10年,又均匀了一些:
MVP七两一钱 计算了三个甲子的生辰之后,能获得骨重最大值七两一钱的只有48个。当时间范围缩小到有现实意义的1960年至今,则只有16个。
假设有一个人,要想获得这个最大值,有下面这些条件:
出生于戊午年或者是己卯年,获得一两九钱
出生于农历的三月或者九月,获得一两八钱
出生于农历的十八或者二十六,获得一两八钱
出生于子时或者是巳时,获得一两六钱重
最后,就能获得七两一钱。
那都有哪些生辰能有这个殊荣呢?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 mysql> select * from shengchen where weight = 71 and datetime > '1960-1-1' and datetime < '2022-12-31'; +--------+---------------------+-----------+------------+----------+---------+--------+ | key | datetime | year8Char | lunarMonth | lunarDay | shichen | weight | +--------+---------------------+-----------+------------+----------+---------+--------+ | 354346 | 1978-04-24 00:00:01 | 戊午 | 3 | 18 | 0 | 71 | | 354351 | 1978-04-24 10:00:01 | 戊午 | 3 | 18 | 5 | 71 | | 354442 | 1978-05-02 00:00:01 | 戊午 | 3 | 26 | 0 | 71 | | 354447 | 1978-05-02 10:00:01 | 戊午 | 3 | 26 | 5 | 71 | | 356482 | 1978-10-19 00:00:01 | 戊午 | 9 | 18 | 0 | 71 | | 356487 | 1978-10-19 10:00:01 | 戊午 | 9 | 18 | 5 | 71 | | 356578 | 1978-10-27 00:00:01 | 戊午 | 9 | 26 | 0 | 71 | | 356583 | 1978-10-27 10:00:01 | 戊午 | 9 | 26 | 5 | 71 | | 446494 | 1999-05-03 00:00:01 | 己卯 | 3 | 18 | 0 | 71 | | 446499 | 1999-05-03 10:00:01 | 己卯 | 3 | 18 | 5 | 71 | | 446590 | 1999-05-11 00:00:01 | 己卯 | 3 | 26 | 0 | 71 | | 446595 | 1999-05-11 10:00:01 | 己卯 | 3 | 26 | 5 | 71 | | 448606 | 1999-10-26 00:00:01 | 己卯 | 9 | 18 | 0 | 71 | | 448611 | 1999-10-26 10:00:01 | 己卯 | 9 | 18 | 5 | 71 | | 448702 | 1999-11-03 00:00:01 | 己卯 | 9 | 26 | 0 | 71 | | 448707 | 1999-11-03 10:00:01 | 己卯 | 9 | 26 | 5 | 71 | +--------+---------------------+-----------+------------+----------+---------+--------+
评骨格歌诀对于这个生辰的评价是:
此命生成大不同,公侯卿相在其中。
有意思的是,尽管这个算法下面的最大值是七两一钱,但是百度百科里面还有关于七两二钱的结果:
此格世界罕有生,十代积善产此人。
更离谱的是,还有七两三钱的:
此命推来天下隆,必定人间一主公。
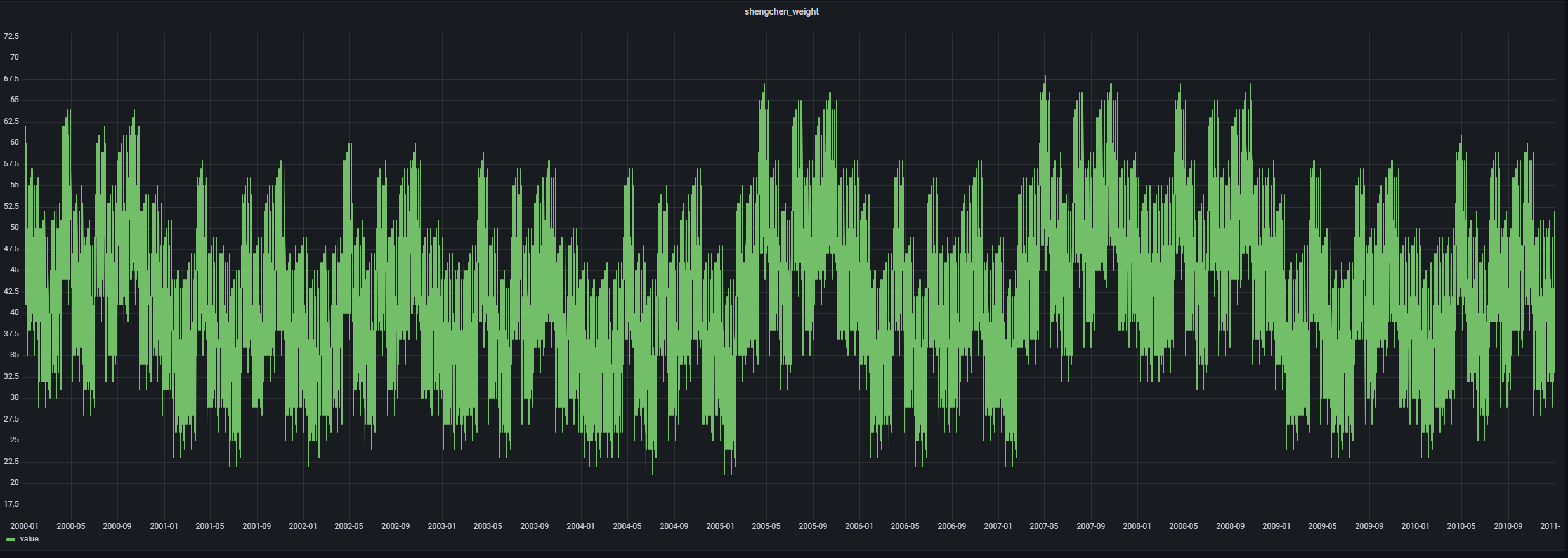
没有意义的趋势 继续以2000-2010年这十年为观察对象,把各个生辰对应的骨重绘成折线图。和预期的一样,平平无奇,在这个尺度之下,呈现出来的波动近似于不同年份的权重变化。
闲聊 笔者从小翻看家里面的旧书《通胜》就认识了不少算命看相的东西,而之所以拿了这个袁天罡称骨算命法作为分析对象,主要是因为这是我看到的唯一一个有量化的结果。其他的测八字定吉凶等各种算命,哪怕是周易文王卦,算出来的各个不同的结果是没有数量属性的,自然也没什么好分析的。
但转念一想,其实这个称骨术这样分析一通,似乎也没有什么有价值的东西。
在做这个数据分析的时候,笔者也上网看了一些针对算命不同的意见,但无意加入讨论。
而这个项目也只是纯粹是周末闲来无事即兴的统计,顺便当做是写代码练练手。
个人看来,这可以归为为古人在探索世界过程中产生的良莠不齐的经验总结,应该平常心看待。这些相术之类的传统文化,可以看作是古代知识分子朴素的唯物主义思想。但如果是一个现代人还捧着这些故纸堆甚至奉为圭臬,陷入宿命论的误区,再大书特写,搞一个论文Quantitative analysis of Yuan Tiangang’s scale bone fortune-telling method using Python and MySQL 就大可不必了。
(笑)