前言 上一年的这个时候, 笔者捣鼓完那个用minikube做的demo用minikube模拟基于Kubernetes平台的容器化改造
现在来填坑了!
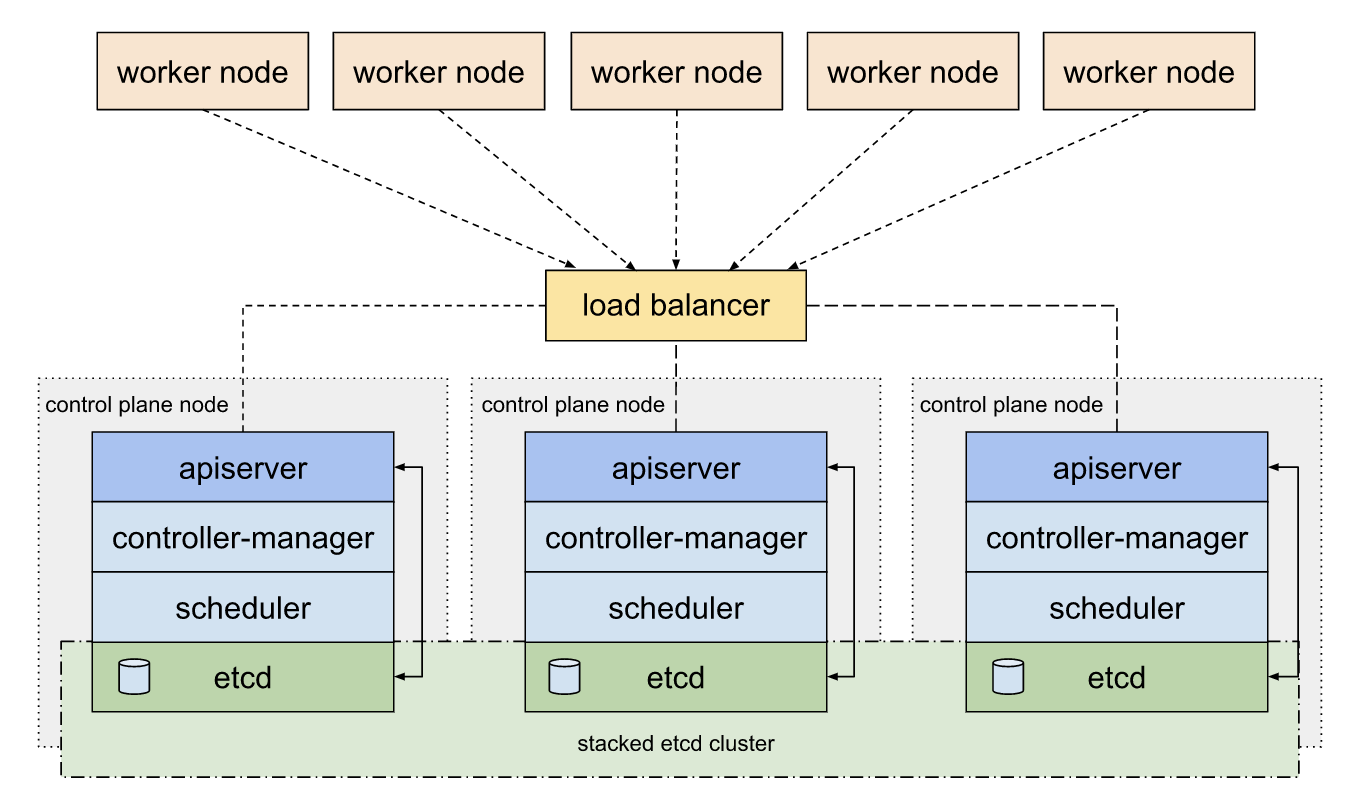
集群简介 架构图
集群概况 为了搭建一个高可用的实验环境, 本环境将会使用6台服务器实例, 硬件配置如下:
项目
内容
操作系统
CentOS 7.9
CPU
2.3 GHz * 2
内存
4 GB
磁盘空间
32 GB
内网网段
192.168.0.0/24
集群内各个服务器的网络设置如下:
节点
角色
IP
k8s-m-1
master
192.168.0.221
k8s-m-2
master
192.168.0.222
k8s-m-3
master
192.168.0.223
null
master-vip
192.168.0.220
k8s-w-1
worker
192.168.0.224
k8s-w-2
worker
192.168.0.225
k8s-w-3
worker
192.168.0.226
用到的各个k8s和容器组件版本或设置内容如下:
软件
版本/设置内容
containerd
1.6.8
kubectl
v1.25.2
kubeadm
v1.25.2
kubelet
v1.25.2
calico组件
v3.24.3
pod cidr
172.16.0.0/16
service cidr
10.1.0.0/16
HAProxy
1.5.18 (很旧的版本了, 但不是重点)
keepalived
v1.3.5 (同上 ;-) )
前期准备步骤 操作系统初始化 笔者使用的是CentOS7操作系统, 操作系统安装完成后, 需要进行的初始化设置有:
在各个服务器妥善设置唯一hostname, 唯一UUID(/sys/class/dmi/id/product_uuid), 唯一MAC地址
确保集群内各节点网络互通, 处于同一内网
禁用swap
安装必要的命令行工具, 例如: yum groupinstall 'development tools'
使用ntp工具完成时间校对
禁用SELinux sudo setenforce 0 && sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
设置内核参数1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf overlay br_netfilter EOF sudo modprobe overlay sudo modprobe br_netfilter cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-iptables = 1 net.bridge.bridge-nf-call-ip6tables = 1 net.ipv4.ip_forward = 1 EOF sudo sysctl --system
为master节点安装keepalived和HAProxy 本集群主要用于演示和实验目的, 所以高可用的设置也采取了通用的keepalived + HAProxy方案, 详细安装方法可以参考: ha-considerations
笔者直接使用yum命令安装:
1 yum install keepalived haproxy
keepalived配置示例 本集群使用的keepalived.conf内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 global_defs { router_id LVS_DEVEL } vrrp_script check_apiserver { script "/etc/keepalived/check_apiserver.sh" interval 3 weight -2 fall 10 rise 2 } vrrp_instance VI_1 { state MASTER interface eth0 virtual_router_id 51 priority 100 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.0.220 } track_script { check_apiserver } }
相应地, 健康检查脚本check_apiserver.sh内容如下(注意为脚本设置好权限):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #!/bin/sh errorExit() { echo "*** $*" 1>&2 exit 1 } APISERVER_DEST_PORT=8443 APISERVER_VIP=192.168.0.220 curl --silent --max-time 2 --insecure https://localhost:${APISERVER_DEST_PORT}/ -o /dev/null || errorExit "Error GET https://localhost:${APISERVER_DEST_PORT}/" if ip addr | grep -q ${APISERVER_VIP}; then curl --silent --max-time 2 --insecure https://${APISERVER_VIP}:${APISERVER_DEST_PORT}/ -o /dev/null || errorExit "Error GET https://${APISERVER_VIP}:${APISERVER_DEST_PORT}/" fi
HAProxy配置示例 配置文件haproxy.cfg内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #--------------------------------------------------------------------- # Global settings #--------------------------------------------------------------------- global log /dev/log local0 log /dev/log local1 notice daemon #--------------------------------------------------------------------- # common defaults that all the 'listen' and 'backend' sections will # use if not designated in their block #--------------------------------------------------------------------- defaults mode http log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 1 timeout http-request 10s timeout queue 20s timeout connect 5s timeout client 20s timeout server 20s timeout http-keep-alive 10s timeout check 10s #--------------------------------------------------------------------- # apiserver frontend which proxys to the control plane nodes #--------------------------------------------------------------------- frontend apiserver bind *:8443 mode tcp option tcplog default_backend apiserver #--------------------------------------------------------------------- # round robin balancing for apiserver #--------------------------------------------------------------------- backend apiserver option httpchk GET /healthz http-check expect status 200 mode tcp option ssl-hello-chk balance roundrobin server k8s-m-1 192.168.0.221:6443 check server k8s-m-2 192.168.0.222:6443 check server k8s-m-3 192.168.0.223:6443 check
为所有节点安装containerd容器运行环境 为什么选择containerd 在撰文之前, 笔者随便在百度搜了一下类似的文章, 大多数都仍然在用docker, 就想着要不要试试看别的.
在之前的文章 docker build出来的镜像文件.
containerd安装过程 安装过程可以参考containerd的github文档: Getting started with containerd
笔者是通过yum源安装的, 有点滑稽的是, containerd的官方yum源是由docker去维护的.
1 2 3 4 5 sudo yum install -y yum-utils sudo yum-config-manager \ --add-repo \ https://download.docker.com/linux/centos/docker-ce.repo sudo yum install containerd.io
设置containerd 安装完成后, 生成containerd的默认配置文件:
1 containerd config default > /etc/containerd/config.toml
如果需要考虑要设置自定义镜像源, 可以参考: containerd-registry
但是, 我们只是安装containerd这个运行环境, 具体的容器编排是通过k8s完成的, 所以就不用在containerd的配置中纠结镜像源的问题了.
为所有节点安装K8s命令行工具 官网有详细的说明文档: install-kubeadm
但推荐大家使用阿里云的k8s yum源, 避免网络问题导致安装失败:
1 2 3 4 5 6 7 8 9 10 11 12 13 cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg exclude=kubelet kubeadm kubectl EOF sudo yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes sudo systemctl enable --now kubelet
部分特殊设置 设置Cgroup drivers为systemd 这个可以留坑, 后面慢慢讨论这是做什么的. 但官方文档里面有这么一句:
The cgroupfs driver is not recommended when systemd is the init system because systemd expects a single cgroup manager on the system.
所以我们需要把Cgroup driver设置为systemd, 按照官方文档操作就可以: cgroup-drivers
提前下载阿里云镜像 在国内的网络下是不能直接下载k8s官网的镜像的, 需要用参数指定阿里云的镜像源. 另外我们可以看到, 在这个版本的默认配置下, 会下载pause:3.8的镜像, 后面要用到.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [root@k8s-m-1 ~]# kubeadm config images list registry.k8s.io/kube-apiserver:v1.25.3 registry.k8s.io/kube-controller-manager:v1.25.3 registry.k8s.io/kube-scheduler:v1.25.3 registry.k8s.io/kube-proxy:v1.25.3 registry.k8s.io/pause:3.8 registry.k8s.io/etcd:3.5.4-0 registry.k8s.io/coredns/coredns:v1.9.3 [root@k8s-m-1 ~]# kubeadm config images pull --image-repository registry.aliyuncs.com/google_containers [config/images] Pulled registry.aliyuncs.com/google_containers/kube-apiserver:v1.25.3 [config/images] Pulled registry.aliyuncs.com/google_containers/kube-controller-manager:v1.25.3 [config/images] Pulled registry.aliyuncs.com/google_containers/kube-scheduler:v1.25.3 [config/images] Pulled registry.aliyuncs.com/google_containers/kube-proxy:v1.25.3 [config/images] Pulled registry.aliyuncs.com/google_containers/pause:3.8 [config/images] Pulled registry.aliyuncs.com/google_containers/etcd:3.5.4-0 [config/images] Pulled registry.aliyuncs.com/google_containers/coredns:v1.9.3
设置SandBox Pause镜像 在上一个步骤的基础上, 我们需要指定容器Runtime的sandbox_image, 在本例中, 笔者的设置如下:
1 2 3 4 5 6 7 8 # /etc/containerd/config.toml ... [plugins] [plugins."io.containerd.grpc.v1.cri"] ... sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.8" ...
详细可以参考: container-runtimes#override-pause-image-containerd
另外, 就算没有版本冲突的问题, 笔者也建议关注一下这个配置. 如果使用默认配置, containerd会下载k8s.gcr.io/pause:3.6镜像, 同样会因为网络问题而影响后面k8s集群的初始化.
当时笔者是下意识认为只是简单的网络问题, 就给containerd设置了https_proxy环境变量去把镜像下载了, 但是后面又因为这个https_proxy环境变量影响了containerd和k8s集群的一些网络功能.
相比较之下, 修改配置文件直接从国内的镜像源下载才是最科学的方案.
附: 因网络问题导致镜像下载失败的日志内容:
1 Oct 16 17:38:37 k8s-m-1 containerd[1431]: time="2022-10-16T17:38:37.663046115+08:00" level=error msg="RunPodSandbox for &PodSandboxMetadata{Name:kube-scheduler-k8s-m-1,Uid:92c0bde2d34bb6b7b7633f598dd71b29,Namespace:kube-system,Attempt:0,} failed, error" error="failed to get sandbox image \"k8s.gcr.io/pause:3.6\": failed to pull image \"k8s.gcr.io/pause:3.6\": failed to pull and unpack image \"k8s.gcr.io/pause:3.6\": failed to resolve reference \"k8s.gcr.io/pause:3.6\": failed to do request: Head \"https://k8s.gcr.io/v2/pause/manifests/3.6\": dial tcp 74.125.142.82:443: i/o timeout"
可以开始设置快照模板或者复制虚拟机了. 上面提到的这些准备工作, 是需要在多个节点去重复操作的, 大家可以根据自己的环境使用虚拟平台的克隆功能去加快效率, 但是注意要做好hostname和MAC地址的区分.
笔者的准备工作步骤可供大家参考:
用CentOS7 Minimal官方镜像创建一台虚拟机
网卡的IPv4和DNS使用静态配置
yum update -y && yum groupinstall 'Development Tools' -y , 再按照习惯安装其他工具进行操作系统基础设置: 设置允许免密码登录的rsa公钥, 做好sudoer设置, 禁用firewalld.service, 检查ntpd等等…
安装containerd, K8s命令行工具, 并做好必要的特殊设置
把当前的虚拟机实例设置成模板, 后面k8s集群所有新增的节点都用这个模板进行克隆
克隆出6个节点, 完成必要的调整
为master节点安装keepalived和haproxy, 并妥善配置
为方案中预设的master vip 192.168.0.220设置一个域名: dev.i.k8s.rondochen.com. (因为解析出来只是个内网ip, 就算是一个公网域名, 没有什么安全隐患)
为集群内所有即将要安装k8s的节点做一个快照, 出问题之后方便回滚
上面的步骤都做完之后, 我们即将可以进行集群的初始化了
Tips: 也安装一个ansible工具去对集群机器实现批量操作
Kubernetes 集群安装 集群初始化 先在所有节点都启动containerd.service
1 2 systemctl start containerd.service; systemctl enable containerd.service
在k8s-m-1节点, 运行下面的集群初始化命令:
1 2 3 4 5 6 7 kubeadm init \ --pod-network-cidr=172.16.0.0/16 \ --service-cidr=10.1.0.0/16 \ --image-repository registry.aliyuncs.com/google_containers \ --apiserver-advertise-address 192.168.0.221 \ --control-plane-endpoint dev.i.k8s.rondochen.com:8443 \ --upload-certs
为了避免网络冲突, 我们需要用--pod-network-cidr指定pod的子网网段, 而k8s默认会为每个node的pod分配一个C类地址. 所以在集群初始化的时候, 作为新手, 为了避免其他麻烦, 在指定--pod-network-cidr的时候最好使用一个子网掩码小于24位的网段.
关于地址分配的经验, 可以参考:
https://kubernetes.io/blog/2022/05/23/service-ip-dynamic-and-static-allocation/
https://cloud.google.com/kubernetes-engine/docs/how-to/flexible-pod-cidr
命令运行的时候, 会弹出很多日志, 到最后还会有一些操作提示, 我们都可以照做:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ You can now join any number of the control-plane node running the following command on each as root: kubeadm join dev.i.k8s.rondochen.com:8443 --token 0uzrqr.9sbeyk3uppma02iu \ --discovery-token-ca-cert-hash sha256:8da6a482384ff0037417fde61c02c16e6c68577a7f9b641e06d0bcab5162c17c \ --control-plane --certificate-key 107f4125a2ad3cf16c84ad620def6cd3fbd9928ac2a7c671ccd433c164e99360 Please note that the certificate-key gives access to cluster sensitive data, keep it secret! As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use "kubeadm init phase upload-certs --upload-certs" to reload certs afterward. Then you can join any number of worker nodes by running the following on each as root: kubeadm join dev.i.k8s.rondochen.com:8443 --token 0uzrqr.9sbeyk3uppma02iu \ --discovery-token-ca-cert-hash sha256:8da6a482384ff0037417fde61c02c16e6c68577a7f9b641e06d0bcab5162c17c
到这里, k8s-m-1节点的k8s安装就完成了, 接下来要安装网络插件, 本例使用的是calico.
安装calico网络插件 参考calico的文档, 很快就安装好了: Install Calico Quickstart
1 2 3 # 文档里面的指引是下面两个命令, 但最好是把yaml文件下载到本地再执行 kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.24.3/manifests/tigera-operator.yaml kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.24.3/manifests/custom-resources.yaml
另外要注意, 需要对文件custom-resources.yaml IP pool CIDR部分. 另外为了避免BGP连接失败, 笔者再添加了一个nodeAddressAutodetectionV4配置.
本例使用的custom-resources.yaml文件内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 apiVersion: operator.tigera.io/v1 kind: Installation metadata: name: default spec: calicoNetwork: ipPools: - blockSize: 26 cidr: 172.16 .0 .0 /16 encapsulation: VXLANCrossSubnet natOutgoing: Enabled nodeSelector: all() nodeAddressAutodetectionV4: interface: "eth*" --- apiVersion: operator.tigera.io/v1 kind: APIServer metadata: name: default spec: {}
Tips: 这个安装过程可能会有一些各种各样的问题, 灵活使用搜索引擎, 或者尝试重启一下containerd.service, 基本上都能解决.
笔者遇到过这个问题: calico/node is not ready: BIRD is not ready: BGP not established
CNI插件安装完成后, 这个master节点就已经完成部署了. 在默认情况下, 集群不会在master节点上调度业务pod, 但如果你只想用一个单节点测试运行, 需要运行这个命令:
1 kubectl taint nodes --all node-role.kubernetes.io/control-plane-
最后, 我们可以看到, 节点已经处于Ready状态:
1 2 3 $ kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-m-1 Ready control-plane 19m v1.25.2
加入更多节点 在前面master节点初始化完成后, stdout已经给出提示, 抄答案运行kubeadm join命令就可以了, 但要注意token是有有效期的.
但如果遇到token已经过期了, 可以重新创建一个:
1 kubeadm token create --print-join-command
如果certificate-key过期或者考虑到信息安全, 也可以手动同步证书, 可以参考: manual-certs
到最后, 这个6节点的k8s集群, 状态这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 [rondo@k8s-m-1 ~]$ kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-m-1 Ready control-plane 81m v1.25.2 k8s-m-2 Ready control-plane 60m v1.25.2 k8s-m-3 Ready control-plane 48m v1.25.2 k8s-w-1 Ready <none> 66m v1.25.2 k8s-w-2 Ready <none> 26m v1.25.2 k8s-w-3 Ready <none> 41m v1.25.2 [rondo@k8s-m-1 ~]$ kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE calico-apiserver calico-apiserver-6f4d5fcbd4-p22gg 1/1 Running 0 81m calico-apiserver calico-apiserver-6f4d5fcbd4-shhjd 1/1 Running 0 81m calico-system calico-kube-controllers-d89c6cdb4-kh7dr 1/1 Running 0 81m calico-system calico-node-2rs9w 1/1 Running 4 (69m ago) 65m calico-system calico-node-frjz2 1/1 Running 0 81m calico-system calico-node-m2wwm 1/1 Running 0 26m calico-system calico-node-mlp27 1/1 Running 0 71m calico-system calico-node-tt2zq 1/1 Running 0 41m calico-system calico-node-xrx6k 1/1 Running 1 (59m ago) 54m calico-system calico-typha-54499596d9-7gjlf 1/1 Running 0 41m calico-system calico-typha-54499596d9-cpb52 1/1 Running 0 81m calico-system calico-typha-54499596d9-mfk7q 1/1 Running 0 65m kube-system coredns-c676cc86f-96mkp 1/1 Running 0 86m kube-system coredns-c676cc86f-t6px8 1/1 Running 0 86m kube-system etcd-k8s-m-1 1/1 Running 4 86m kube-system etcd-k8s-m-2 1/1 Running 0 65m kube-system etcd-k8s-m-3 1/1 Running 0 53m kube-system kube-apiserver-k8s-m-1 1/1 Running 0 86m kube-system kube-apiserver-k8s-m-2 1/1 Running 4 (71m ago) 65m kube-system kube-apiserver-k8s-m-3 1/1 Running 9 (59m ago) 54m kube-system kube-controller-manager-k8s-m-1 1/1 Running 0 86m kube-system kube-controller-manager-k8s-m-2 1/1 Running 1 65m kube-system kube-controller-manager-k8s-m-3 1/1 Running 1 54m kube-system kube-proxy-2lq45 1/1 Running 0 26m kube-system kube-proxy-88ztr 1/1 Running 0 86m kube-system kube-proxy-gqm9d 1/1 Running 0 54m kube-system kube-proxy-q52ts 1/1 Running 0 41m kube-system kube-proxy-xlddg 1/1 Running 0 71m kube-system kube-proxy-z62jv 1/1 Running 0 65m kube-system kube-scheduler-k8s-m-1 1/1 Running 1 86m kube-system kube-scheduler-k8s-m-2 1/1 Running 1 65m kube-system kube-scheduler-k8s-m-3 1/1 Running 1 54m tigera-operator tigera-operator-7659dcc9f4-v84vv 1/1 Running 0 84m
因为使用的是calico网络插件, 我们还需要关注一下BGP的状态:
安装calicoctl工具
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [root@k8s-m-1 ~]# calicoctl node status Calico process is running. IPv4 BGP status +---------------+-------------------+-------+----------+-------------+ | PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO | +---------------+-------------------+-------+----------+-------------+ | 192.168.0.222 | node-to-node mesh | up | 11:55:57 | Established | | 192.168.0.223 | node-to-node mesh | up | 11:55:59 | Established | | 192.168.0.224 | node-to-node mesh | up | 11:55:57 | Established | | 192.168.0.225 | node-to-node mesh | up | 11:55:57 | Established | | 192.168.0.226 | node-to-node mesh | up | 11:55:56 | Established | +---------------+-------------------+-------+----------+-------------+ IPv6 BGP status No IPv6 peers found.
在最后, 考虑到集群宕机自愈的问题, 我们还需要设置kubelet.service开机自动启动:
1 sudo systemctl enable kubelet.service
测试k8s集群 在之前的文章设计一个golang项目的容器构建流程 dockerhub-rondochen-go-demo-app
在k8s录入镜像仓库信息 先创建一个namespace:
1 kubectl create namespace dev
把dockerhub的接入配置录入k8s, 在这里, 创建一个secret类型的资源, 命名为rondo-dockerhub:
1 2 3 4 5 6 7 8 9 10 kubectl -n dev create secret docker-registry rondo-dockerhub \ --docker-server=docker.io \ --docker-username=rondochen \ --docker-password='xxxxxxxxx' \ --docker-email=my-email@e-mail.com $ kubectl get secret -n dev NAME TYPE DATA AGE rondo-dockerhub kubernetes.io/dockerconfigjson 1 31s
使用deployment部署pod 简简单单写一个deployment:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 apiVersion: apps/v1 kind: Deployment metadata: name: mydemo namespace: dev spec: replicas: 2 selector: matchLabels: app: mydemo template: metadata: labels: app: mydemo spec: containers: - image: rondochen/go-demo-app:multistage name: mydemo ports: - name: mydemo-port containerPort: 3000 protocol: TCP imagePullSecrets: - name: rondo-dockerhub
顺利创建pod:
1 2 3 4 5 6 [rondo@k8s-m-1 demo]$ kubectl apply -f deployment-golang-demo.yaml deployment.apps/mydemo created [rondo@k8s-m-1 demo]$ kubectl get pods -n dev NAME READY STATUS RESTARTS AGE mydemo-6bcbf84f98-f8vs2 1/1 Running 0 11s mydemo-6bcbf84f98-nfrnq 1/1 Running 0 11s
创建service 再简简单单写一个service, 类型是NodePort, 允许集群外访问:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 apiVersion: v1 kind: Service metadata: name: svc-mydemo namespace: dev labels: app: mydemo spec: selector: app: mydemo ports: - protocol: TCP port: 80 targetPort: 3000 type: NodePort
Service创建成功:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 [rondo@k8s-m-1 ~]$ kubectl get service -n dev NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc-mydemo NodePort 10.1.127.64 <none> 80:30120/TCP 14m [rondo@k8s-m-1 ~]$ kubectl describe service svc-mydemo -n dev Name: svc-mydemo Namespace: dev Labels: app=mydemo Annotations: <none> Selector: app=mydemo Type: NodePort IP Family Policy: SingleStack IP Families: IPv4 IP: 10.1.127.64 IPs: 10.1.127.64 Port: <unset> 80/TCP TargetPort: 3000/TCP NodePort: <unset> 30120/TCP Endpoints: 172.16.196.65:3000,172.16.47.1:3000 Session Affinity: None External Traffic Policy: Cluster Events: <none>
验收 我们在上面的输出可以看到, 这个service已经完成了30120:80的端口映射, 可以在集群外访问. 目标地址可以是集群内随便一个节点的host IP:
1 2 3 4 5 6 7 8 9 10 11 12 [root@gen10 ~]# curl 192.168.0.221:30120 Hello, Docker! <3[root@gen10 ~]# [root@gen10 ~]# curl 192.168.0.222:30120 Hello, Docker! <3[root@gen10 ~]# [root@gen10 ~]# [root@gen10 ~]# curl 192.168.0.220:30120 Hello, Docker! <3[root@gen10 ~]# [root@gen10 ~]# [root@gen10 ~]# curl 192.168.0.225:30120 Hello, Docker! <3[root@gen10 ~]# [root@gen10 ~]# curl 192.168.0.226:30120/ping {"Status":"OK"}
后记 笔者当初是在云平台上面现成的k8s环境中入门的, 一直以来工作的都侧重于对业务的编排上, 趁着这个机会也算是补充了一些底层的系统知识.
尽管已经很努力地想把更多的经验分享出来, 但考虑到行文的流畅, 还是省略了很多内容. 要说经验分享, 也只能告诉大家要善用搜索引擎.
在整个过程中, 有很多值得讨论的细节内容都被略过了, 后面有机会再慢慢写写.
拾遗 daemonset/csi-node-driver 创建pod失败 集群创建好了之后, 检查event发现有这样的Warning:
1 2 3 [rondo@k8s-m-1 ~]$ kubectl get events -n calico-system LAST SEEN TYPE REASON OBJECT MESSAGE 14m Warning FailedCreate daemonset/csi-node-driver Error creating: pods "csi-node-driver-" is forbidden: error looking up service account calico-system/csi-node-driver: serviceaccount "csi-node-driver" not found
再检查发现, csi-node-driver这个daemonset确实没能正确运行:
1 2 3 4 [rondo@k8s-m-1 ~]$ kubectl get daemonset -n calico-system NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE calico-node 6 6 6 6 6 kubernetes.io/os=linux 7d19h csi-node-driver 0 0 0 0 0 kubernetes.io/os=linux 7d19h
要修复也好容易:
1 2 3 4 5 6 7 8 9 [rondo@k8s-m-1 ~]$ kubectl create serviceaccount csi-node-driver -n calico-system serviceaccount/csi-node-driver created [rondo@k8s-m-1 ~]$ kubectl get serviceaccount -n calico-system NAME SECRETS AGE calico-kube-controllers 0 7d19h calico-node 0 7d19h calico-typha 0 7d19h csi-node-driver 0 2s default 0 7d19h
接下来, 就看到daemonset成功把pod启动出来了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 [rondo@k8s-m-1 ~]$ kubectl get daemonset -n calico-system NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE calico-node 6 6 6 6 6 kubernetes.io/os=linux 7d20h csi-node-driver 6 6 6 6 6 kubernetes.io/os=linux 7d20h [rondo@k8s-m-1 ~]$ kubectl get pods -n calico-system NAME READY STATUS RESTARTS AGE calico-kube-controllers-d89c6cdb4-tlhmn 1/1 Running 0 4h52m calico-node-fwmnv 1/1 Running 1 (7d20h ago) 7d20h calico-node-hdpq8 1/1 Running 1 (7d20h ago) 7d20h calico-node-qgjx2 1/1 Running 1 (7d20h ago) 7d20h calico-node-r7f25 1/1 Running 1 (7d20h ago) 7d20h calico-node-tw6t6 1/1 Running 1 (7d20h ago) 7d20h calico-node-vjrlq 1/1 Running 1 (7d20h ago) 7d20h calico-typha-549d579bf8-2crdn 1/1 Running 2 (7d20h ago) 7d20h calico-typha-549d579bf8-h8rnn 1/1 Running 2 (7d20h ago) 7d20h calico-typha-549d579bf8-j48gx 1/1 Running 3 (7d20h ago) 7d20h csi-node-driver-88h74 2/2 Running 0 67m csi-node-driver-dn68t 2/2 Running 0 67m csi-node-driver-gc6tk 2/2 Running 0 67m csi-node-driver-gm75x 2/2 Running 0 67m csi-node-driver-gpllc 2/2 Running 0 67m csi-node-driver-mx94k 2/2 Running 0 67m
check_apiserver.sh 端口讨论 在上面的内容 check_apiserver.sh, 里面有一个变量APISERVER_DEST_PORT, 在本例中使用了8443, 可以讨论一下.
在当前的配置下, 如果vip所在的节点出现宕机, 或者是网络中断, 不论设置的APISERVER_DEST_PORT是哪个端口, 结果都能触发keepalived的重新选举, 不影响集群的运行. 但如果是vip节点服务器运行正常, 网络也未曾中断, 仅仅是6443或者8443其中一个端口不可达这种蹊跷的情况呢?
本质上这是一个逻辑问题, 把这个问题抽象化, 我们要讨论的是:
已知, APISERVER_DEST_PORT不可达是keepalived重新选举的充要条件, APISERVER_DEST_PORT的设置会对集群的运行有何影响.
假如设置的APISERVER_DEST_PORT是6443 6443即是kube-apiserver的端口, 当vip:6443不可达, 集群固然会在keepalived的作用下重新选举后完成自愈.
但在这个设置下, 当vip:8443即vip所在的节点的HAProxy服务不可达, 而该节点下的kube-apiserver又正常运行的时候, keepalived是不会重新选举的. 结果就是集群的所有节点都会发现dev.i.k8s.rondochen.com:8443不可达, 造成了不可自愈的故障. 并且因为kubectl这个命令也是需要访问dev.i.k8s.rondochen.com:8443这个入口, 所以连kubectl命令都无法正常使用.
在这种情况下修改/etc/kubernetes/admin.conf之后再去查看kubectl get nodes, 结果如下:
1 2 3 4 5 6 7 8 [root@k8s-m-1 kubernetes]# kubectl get nodes NAME STATUS ROLES AGE VERSION k8s-m-1 NotReady control-plane 7d16h v1.25.2 k8s-m-2 NotReady control-plane 7d16h v1.25.2 k8s-m-3 NotReady control-plane 7d16h v1.25.2 k8s-w-1 NotReady <none> 7d16h v1.25.2 k8s-w-2 NotReady <none> 7d16h v1.25.2 k8s-w-3 NotReady <none> 7d16h v1.25.2
假如设置的APISERVER_DEST_PORT是8443 延续上面的思路, 在这个设置下面, 当vip:8443不可达, 即HAProxy出现故障的时候, keepalived会重新选举, 从而实现自愈.
而当vip:6443出现故障, 而HAProxy又正常运行的时候, keepalived虽然不会重新选举, 但在HAProxy的作用下, 流量会分流到服务正常的HAProxy backend下, 不影响集群的运行.
结论 综上所述, 在keepalived的监控脚本中, 我们选择了8443端口作为监控对象.
实验不顺利, 想推倒重来? 通过虚拟化平台的快照功能直接回滚.
或者:
1 2 3 4 5 6 7 8 # 在集群删除一个节点: kubectl drain k8s-w-1 --delete-local-data --force --ignore-daemonsets kubectl delete node k8s-w-1 # 然后到所在的节点下运行: kubeadm reset -f # 到最后再把最后一个master节点也reset掉就可以重新开始了(注意屏幕提示, 可能有一些路径要手动删除).
扩展阅读 https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/high-availability/
https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-join/
https://kubernetes.io/docs/tasks/debug/debug-application/debug-running-pod/
https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-config/
https://kubernetes.io/docs/tasks/administer-cluster/kubeadm/configure-cgroup-driver/
https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands