1. 前言
我们在文章《ELK专题:Day1——最小化搭建ELK集群,采集Nginx日志》中已完成了ELK集群的搭建,并且成功采集到Nginx的日志并显示在Kibana的页面中。但我们发现,在Kibana的页面中,对于采集回来的整段Nginx日志,只作为一个text格式的字段去存储,没有对日志内容进行解析和识别。
我们将会在后面的内容研究和解决这个问题。
集群架构图如下:
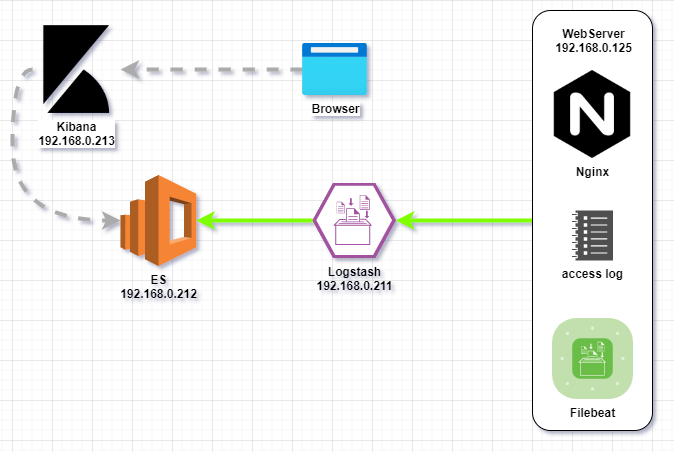
2. 需求分析
2.1 Nginx日志格式
根据官网Module ngx_http_log_module的解析,在默认配置下,Nginx日志使用combined格式:
1
2
3
| log_format combined '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent"';
|
在本实验环境中,Nginx的其中一条access_log内容如下:
1
| 192.168.0.123 - - [11/Aug/2021:09:31:49 +0800] "GET /2021/07/31/ELK1/ HTTP/1.1" 200 17188 "http://192.168.0.125/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36"
|
结合Nginx日志格式配置,我们可以得出以下内容:
|
|
| remote_addr |
192.168.0.123 |
| remote_user |
null |
| time_local |
11/Aug/2021:09:31:49 +0800 |
| request |
GET /2021/07/31/ELK1/ HTTP/1.1 |
| status |
200 |
| body_bytes_sent |
17188 |
| http_referer |
http://192.168.0.125/ |
| http_user_agent |
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 |
2.2 ES中的索引内容
我们在Kibana的页面中可以发现,ES对Nginx日志的识别为一个text字段:
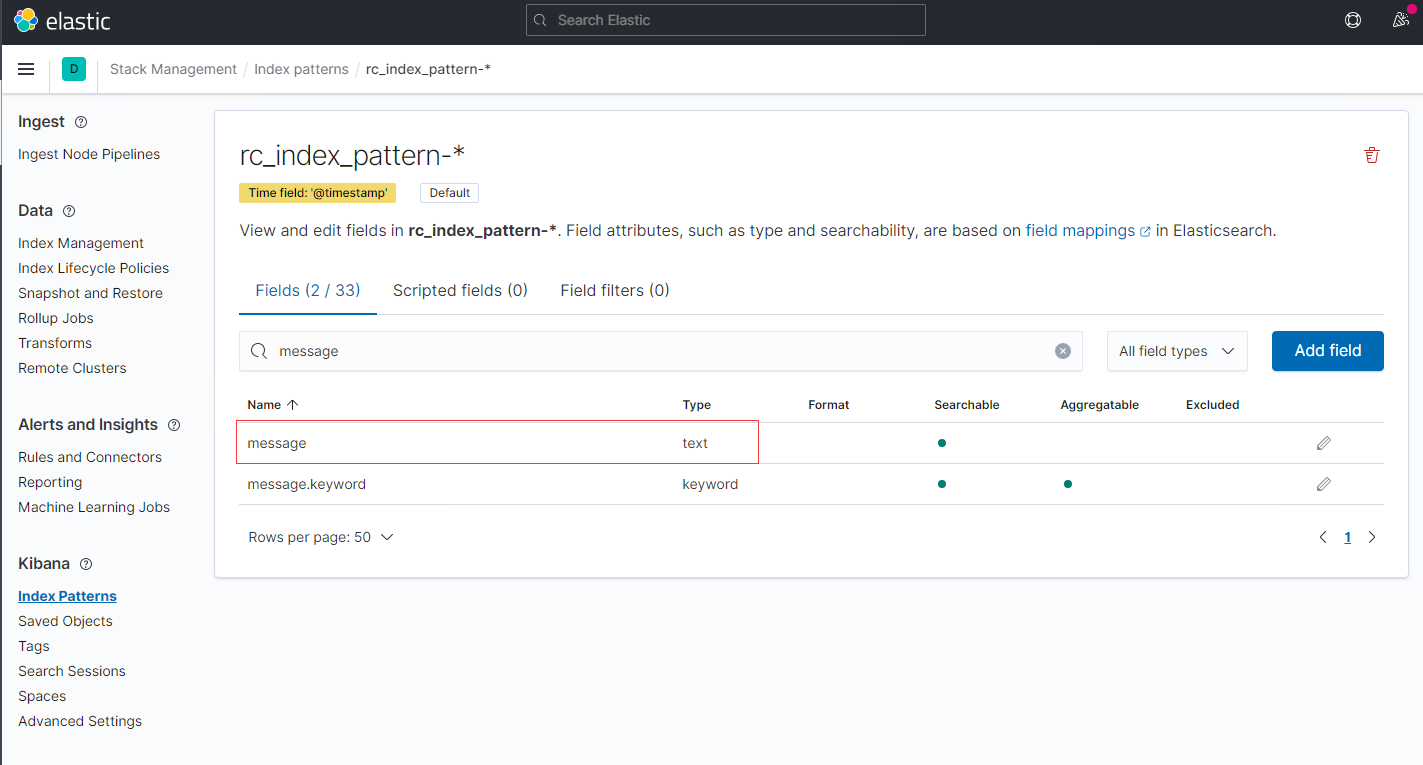
在Kibana的Discover页面中,只选取选取message字段,显示如下:
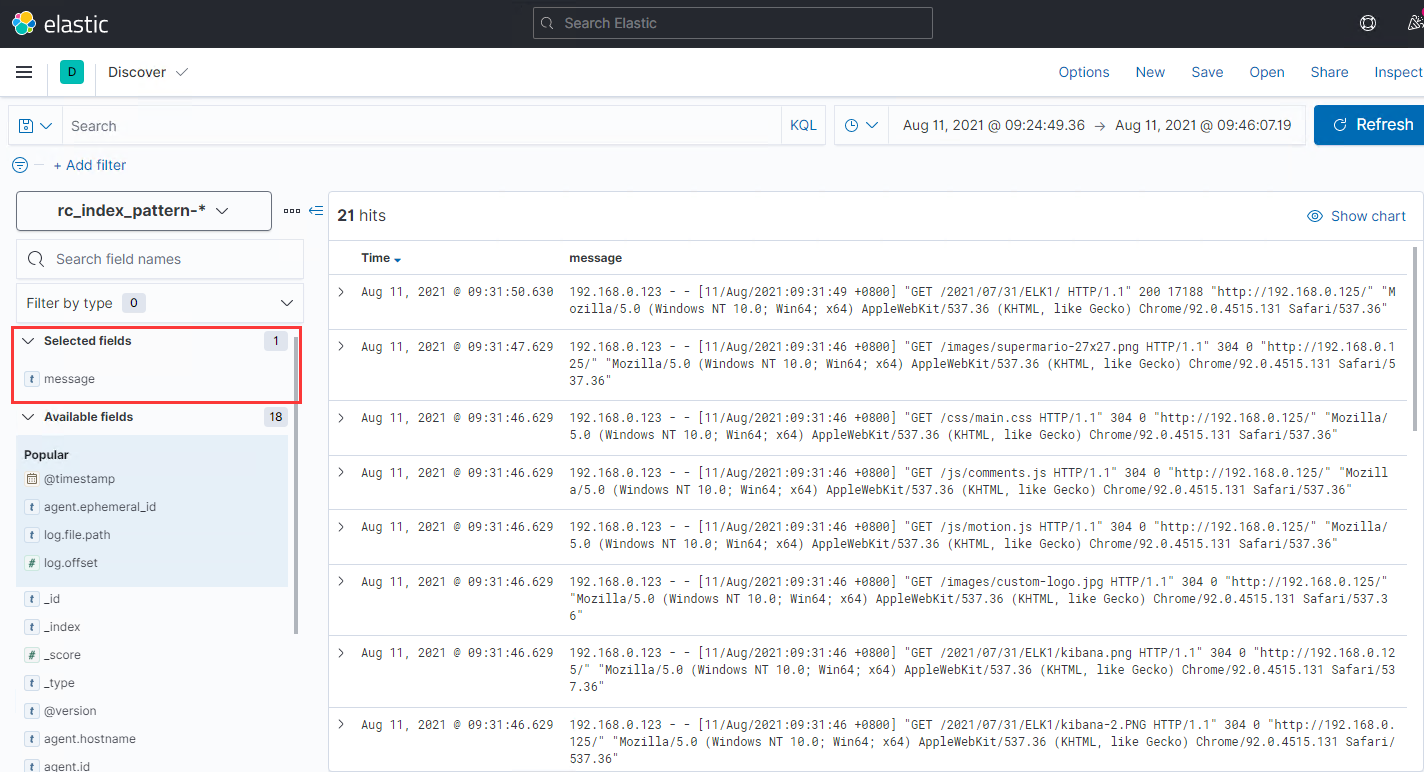
在ES中查看完整的索引内容如下:
点击展开完整json
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
| {
"_index": "rc_index_pattern-2021.08.11",
"_type": "_doc",
"_id": "iPzWMnsB-S8uwXpkUkQ3",
"_version": 1,
"_score": null,
"fields": {
"agent.version.keyword": [
"7.13.4"
],
"input.type.keyword": [
"log"
],
"host.name.keyword": [
"hexo"
],
"tags.keyword": [
"beats_input_codec_plain_applied"
],
"agent.hostname.keyword": [
"hexo"
],
"agent.type": [
"filebeat"
],
"ecs.version.keyword": [
"1.8.0"
],
"@version": [
"1"
],
"agent.name": [
"hexo"
],
"host.name": [
"hexo"
],
"log.file.path.keyword": [
"/var/log/nginx/hexo_access.log"
],
"agent.type.keyword": [
"filebeat"
],
"agent.ephemeral_id.keyword": [
"43714af4-5bf6-43c0-9c1a-4c223fddc273"
],
"agent.name.keyword": [
"hexo"
],
"agent.id.keyword": [
"d2f43da1-5024-4000-9251-0bcc8fc10697"
],
"input.type": [
"log"
],
"@version.keyword": [
"1"
],
"log.offset": [
4678
],
"agent.hostname": [
"hexo"
],
"message": [
"192.168.0.123 - - [11/Aug/2021:09:31:49 +0800] \"GET /2021/07/31/ELK1/ HTTP/1.1\" 200 17188 \"http://192.168.0.125/\" \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36\""
],
"tags": [
"beats_input_codec_plain_applied"
],
"@timestamp": [
"2021-08-11T01:31:50.630Z"
],
"agent.id": [
"d2f43da1-5024-4000-9251-0bcc8fc10697"
],
"ecs.version": [
"1.8.0"
],
"log.file.path": [
"/var/log/nginx/hexo_access.log"
],
"message.keyword": [
"192.168.0.123 - - [11/Aug/2021:09:31:49 +0800] \"GET /2021/07/31/ELK1/ HTTP/1.1\" 200 17188 \"http://192.168.0.125/\" \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36\""
],
"agent.ephemeral_id": [
"43714af4-5bf6-43c0-9c1a-4c223fddc273"
],
"agent.version": [
"7.13.4"
]
},
"sort": [
1628645510630
]
}
|
2.3 问题分析
不难看出,当Nginx的日志存储到ES后,ES并没有对日志内容进行字段划分和内容识别,所以我们无法在Kibana上对日志内容进行检索和统计。
为了解决这个问题,我们可以通过修改Logstash的配置,让日志内容在入库到ES之前,先完成日志内容的字段划分和内容识别。
3. Logstash配置思路
参考How Logstash Works我们可以发现,Logstash可以通过丰富的插件实现日志的识别和字段编排功能。
3.1 怎样修改采集到的日志内容
在Day1的集群搭建过程中,我们的Logstash服务并没有使用filter功能,但在本文的需求里面,想要对采集回来的日志内容在入库之前进行加工,就需要通过filter实现。
3.2 如何对日志内容进行分段和识别
grok是目前在logstash中使用最广泛的插件之一,可以很轻易地识别出文本地结构内容,使其便于检索。
详细介绍:Debugging grok expressions
3.3 如何测试配置的运行结果
我们可以在logstash的output中引用codecs插件,当在logstash中配置了输出到codecs时,通过屏幕打印我们可以知道最终logstash的输出结果。此外,我们还可以再引入不同的格式化插件,如rubydebug,使输出的内容更易于阅读。
3.4 logstsh pipeline配置草稿
结合上面的分析,我们可以初步确定,logstash pipline的测试配置大致如下:
1
2
3
4
5
6
7
| input { stdin { } } #直接使用键盘输入,测试更方便
filter {
grok { } # 使用grok插件
}
output {
stdout { codec => rubydebug } #输出到stdout查看结果
}
|
4. Logstash配置修改
4.1 使用grok识别日志内容
在Kibana页面的主菜单中,有Dev Tools工具,其中就包含Grok Debugger,可以很方便地对日志内容进行调试。
我们在Sample Data输入需要被识别和匹配的Nginx日志:
1
| 192.168.0.123 - - [11/Aug/2021:09:31:49 +0800] "GET /2021/07/31/ELK1/ HTTP/1.1" 200 17188 "http://192.168.0.125/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36"
|
根据日志内容和grok语法,我们可以在Grok Pattern中输入以下内容:
1
| %{IPORHOST:remote_addr} - %{DATA:remote_user} \[%{HTTPDATE:time_local}\] \"%{WORD:request_method} %{DATA:uri} HTTP/%{NUMBER:http_version}\" %{NUMBER:response_code} %{NUMBER:body_sent_bytes} \"%{DATA:http_referrer}\" \"%{DATA:http_user_agent}\"
|
最后点击Simulate,显示识别结果:
点击展开完整json
1
2
3
4
5
6
7
8
9
10
11
12
| {
"remote_addr": "192.168.0.123",
"response_code": "200",
"time_local": "11/Aug/2021:09:31:49 +0800",
"http_version": "1.1",
"request_method": "GET",
"uri": "/2021/07/31/ELK1/",
"http_user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36",
"remote_user": "-",
"body_sent_bytes": "17188",
"http_referrer": "http://192.168.0.125/"
}
|
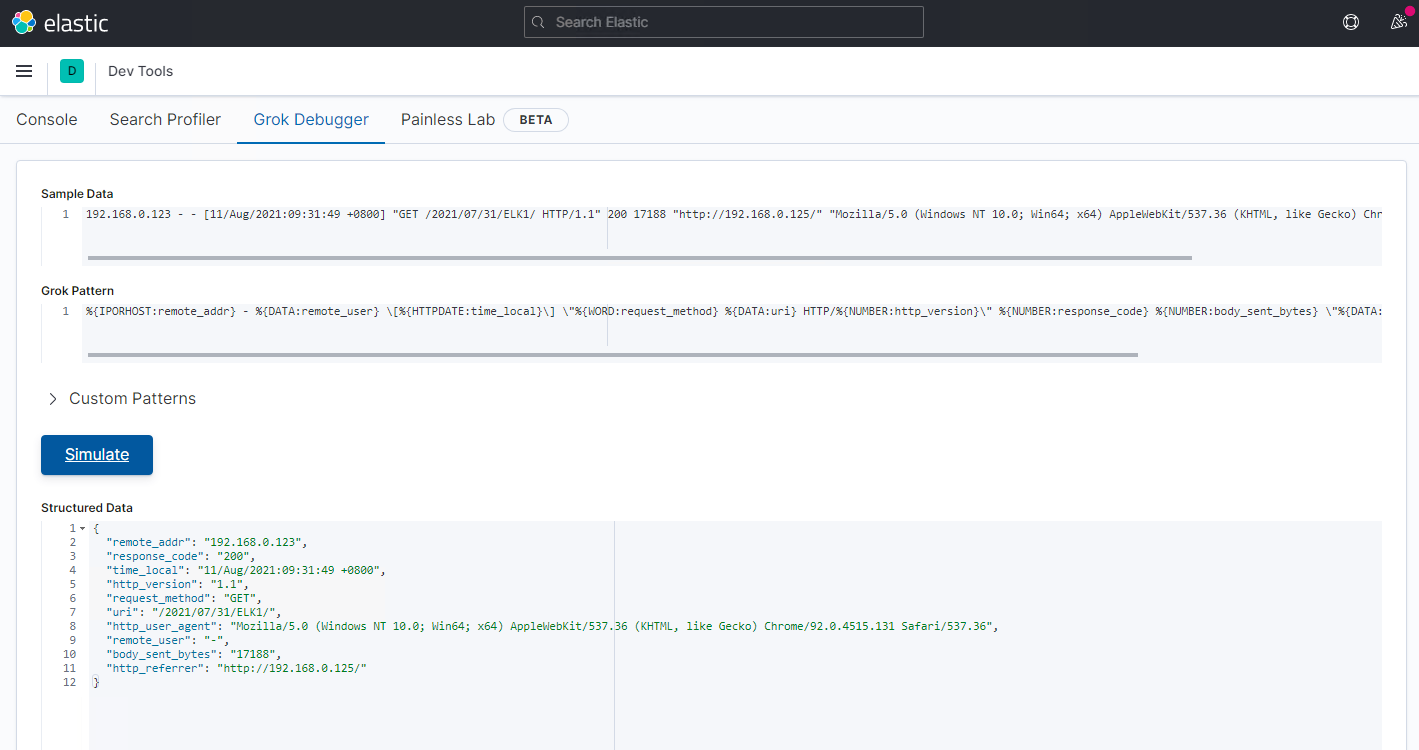
可以看到,grok已经把nginx日志内容中的各个字段内容都正确识别出,json中的各个key将会成为我们在Kibana中看到的各个field。
4.2 测试logstash pipline配置
结合上一节中介绍的调试思路,为了验证logstash能否正确处理日志,我们编写出一个测试配置文件logsta-test.conf,通过键盘输入的方式把日志内容输入到logstash,最后再通过标准输出查看logstash的处理结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
| input { stdin { } }
filter {
grok {
match => { "message" => "%{IPORHOST:remote_addr} - %{DATA:remote_user} \[%{HTTPDATE:time_local}\] \"%{WORD:request_method} %{DATA:uri} HTTP/%{NUMBER:http_version}\" %{NUMBER:response_code} %{NUMBER:body_sent_bytes} \"%{DATA:http_referrer}\" \"%{DATA:http_user_agent}\"" }
}
# 通过date插件,把nginx日志中的时间戳用作logstash的event时间戳
date {
match => [ "time_local", "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
stdout { codec => rubydebug }
}
|
4.3 检查配置文件语法是否正确
我们通过命令行直接启动logstash进程,并且在启动的时候添加--config.test_and_exit参数,检查配置文件是否有语法错误。
完整命令:/usr/share/logstash/bin/logstash --config.test_and_exit -f /root/logstash-test.conf

可以看到,在命令执行最后,屏幕输出Config Validation Result: OK,说明配置文件没有语法错误。
4.4 验证logstash对日志内容识别后的输出结果
使用示例配置logstash-test.conf启动logstash进程,完整命令:
1
| /usr/share/logstash/bin/logstash -f /root/logstash-test.conf
|
当logstash完成初始化后,会有屏显The stdin plugin is now waiting for input:,通过键盘输入把日志内容输入进去,会得到输出结果:
点击展开完整内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| "@version" => "1",
"body_sent_bytes" => "17188",
"message" => "192.168.0.123 - - [11/Aug/2021:09:31:49 +0800] \"GET /2021/07/31/ELK1/ HTTP/1.1\" 200 17188 \"http://192.168.0.125/\" \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36\"",
"request_method" => "GET",
"uri" => "/2021/07/31/ELK1/",
"http_user_agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36",
"host" => "logstash",
"remote_user" => "-",
"time_local" => "11/Aug/2021:09:31:49 +0800",
"http_referrer" => "http://192.168.0.125/",
"response_code" => "200",
"http_version" => "1.1",
"remote_addr" => "192.168.0.123",
"@timestamp" => 2021-08-11T01:31:49.000Z
|

4.5 logstash输出带索引的日志内容到ES
经过上面的测试,我们可以确认logstash已成功完成了对nginx日志内容的分片和识别,我们最后再调整一下配置文件,把经过处理的日志内容最终输出到ES中。
编辑/etc/logstash/conf.d/nginx-es.conf如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| input {
beats {
host => "0.0.0.0"
port => 5400
}
}
filter {
grok {
match => { "message" => "%{IPORHOST:remote_addr} - %{DATA:remote_user} \[%{HTTPDATE:time_local}\] \"%{WORD:request_method} %{DATA:uri} HTTP/%{NUMBER:http_version}\" %{NUMBER:response_code} %{NUMBER:body_sent_bytes} \"%{DATA:http_referrer}\" \"%{DATA:http_user_agent}\"" }
}
date {
match => [ "time_local", "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch {
hosts => ["192.168.0.212:9200"]
index => "rc_index_pattern-%{+YYYY.MM.dd}"
}
}
|
最后启动或重启logstashsudo systemctl start/restart logstash.service
5. 检验成果
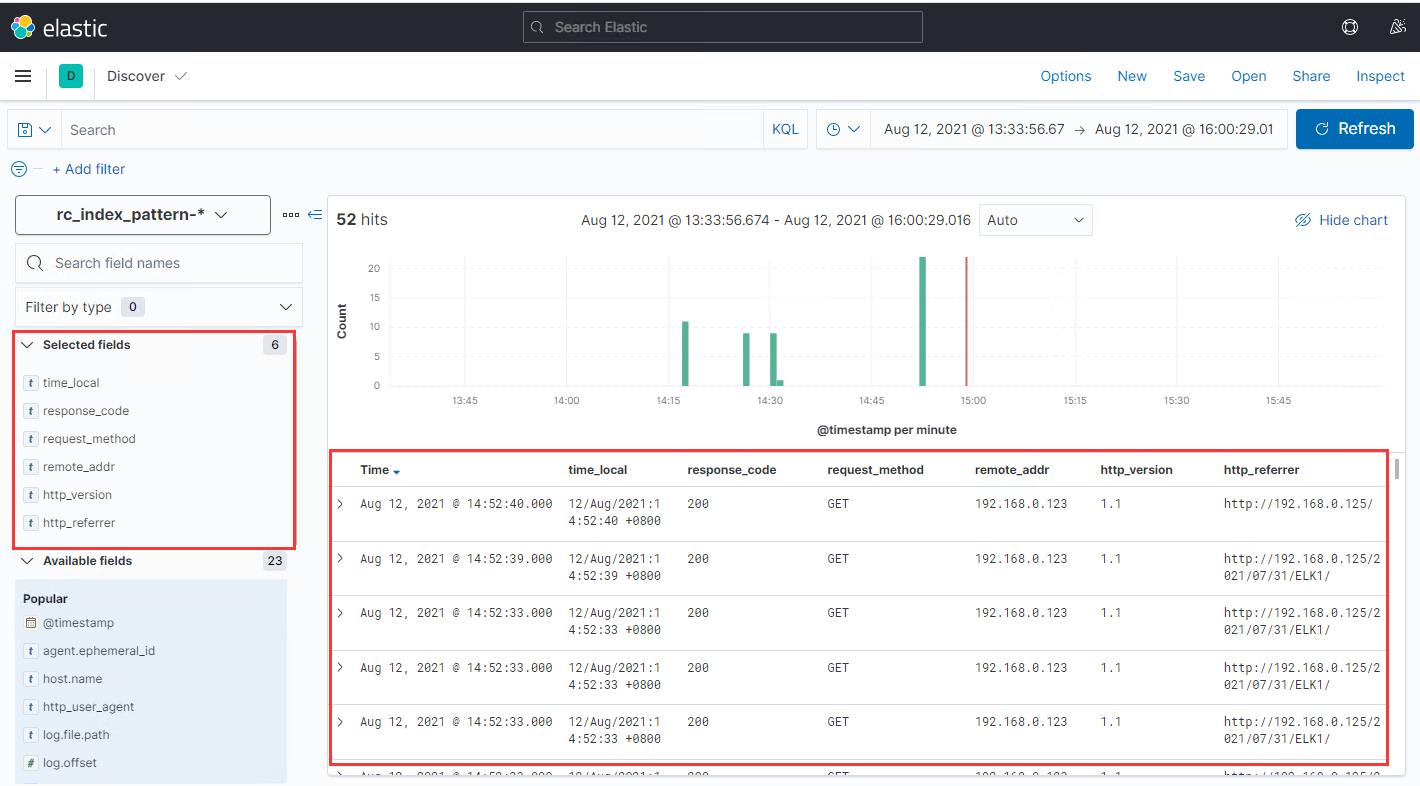
使用浏览器访问测试页面,使其产生访问日志,随后进入kibana页面可以看到最新采集到的日志已经被正确识别(下图):
我们再选取之前没有经过识别的日志内容(下图):
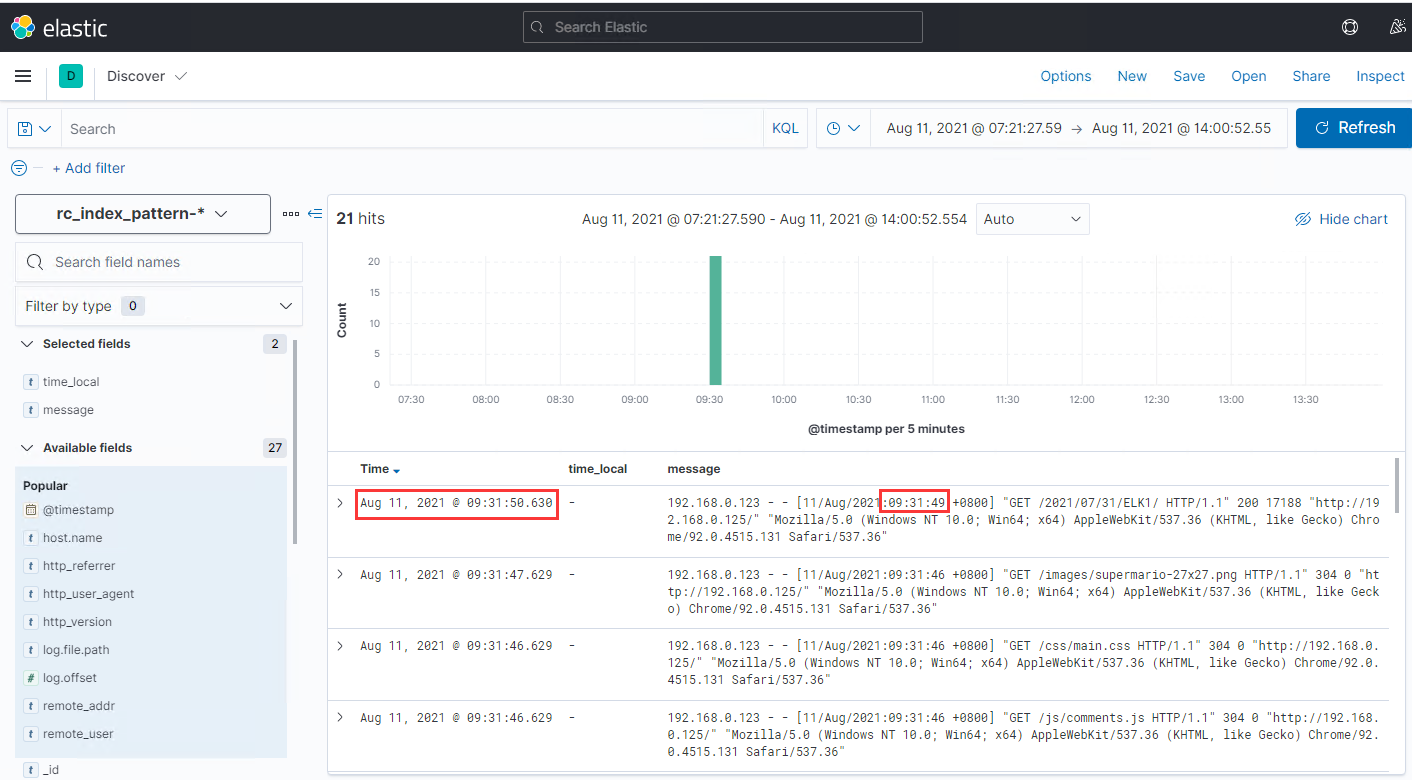
我们可以看到,在对日志内容做索引之前,因为Logstash无法识别出日志内容里面的时间戳,索引只能拿入库到ES的时间作为时间戳,和日志内容里面的实际时间会有1秒左右的差别,这个时间差主要体现在filebeat传输日志和logstash的处理过程上。而当我们完成了日志内容识别后,kibana中显示的时间戳就和日志内容一致了。
6. 总结
本文通过nginx日志分析这个场景,简单介绍了如何通过修改logstash的配置文件,实现对日志内容的字段划分和内容识别,使采集到的日志具备了被检索和统计的可能性。
也通过这个过程简单描述了我们在分析日志内容时候所用到的插件、工具以及思路。
通过这次logstash配置调整,我们便可以在kibana页面中轻易地完成日志内容的筛选。在实际的业务场景中,这一工具可以帮助我们更好地掌握后台的运行情况。
如,我想查看路径/2021/07/31/ELK1/kibana.png在今天的访问记录,则可以在kibana中做这样的搜索:
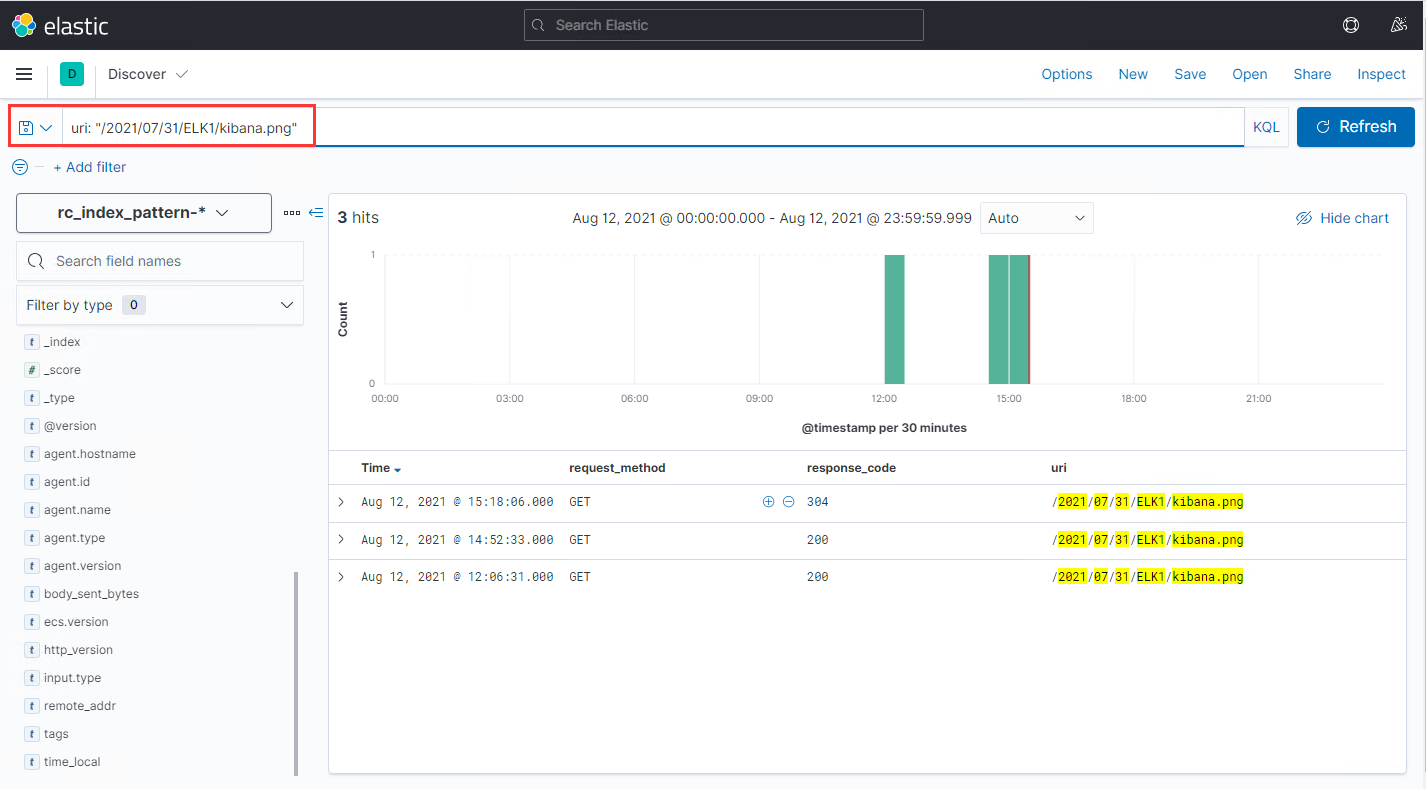
在后面,我们会在日志检索的基础上,继续研究kibana的可视化图表功能,让统计结果可以直观地展示出来。
7. 扩展链接
codec插件
filter插件
grok语法
kibana检索语句KQL